How CVE-2015-7547 (GLIBC getaddrinfo) Can Bypass ASLR
May 27, 2016
10 minutes
39 views
Introduction
On February 16, 2016 Google described a critical vulnerability in GLIBC’s getaddrinfo function. They provided a crash PoC, and so the task of producing a reliable exploit began. In this post, we will show how CVE-2015-7547 can bypass ASLR-enabled systems.
The Bug
getaddrinfo() is used to resolve a hostname and a service to struct addrinfo. This is done by performing a DNS query to get the corresponding IP address(es).
|
1 2 3 4 5 |
int getaddrinfo(const char *node, const char *service, const struct addrinfo *hints, struct addrinfo **res) { ... } |
As an optimization, getaddrinfo()’s implementation uses alloca() function (which allocates a buffer on the stack) for the DNS response. In case the response is too long, it allocates a heap buffer and uses that instead. The bug stems from the fact that, under certain circumstances, the code updates the buffer size to the newly allocated heap buffer but keeps using the old stack buffer pointer. This creates a classic stack-bases overflow.
ASLR? ASLR!
The return address of getaddrinfo can be overwritten using this vulnerability, but where should we point it? In ASLR-enabled systems, module addresses are randomized. Therefore an attacker is not able to set the execution flow to a predefined address. In case the exploited application is compiled with PIE (as it should be), we cannot rely on its main executable to be located at a predefined location.
fork()
The standard way to create new processes in Linux is fork(). A typical fork would look like the following:
|
1 2 3 4 5 6 7 8 |
pid = fork(); if (0 < pid) { /* Parent code goes here... */ } else if (0 == pid) { /* Child code goes here... */ } … |
Code resumes from the same opcode instruction in both parent and child processes. It only differs by the value of “pid”, which is returned by fork(). Unlike Windows, this means that a child process shares many characteristics with its parent -- it has the same register state, stack and memory layout.
Sample Application Flow
Let us consider a server application that acts like the following:
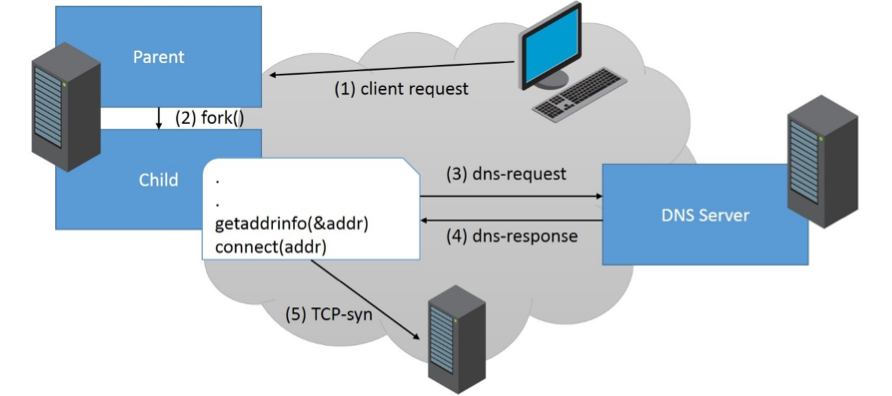
- A client remotely connects to the application.
- In order to handle the client’s request, the application daemon forks itself.
- As part of handling the request, the forked child process resolves a hostname using the “getaddrinfo()" function. Thus, it sends a DNS request to its DNS server.
- DNS server replies with a valid response for the DNS request.
- Child process initiates a connection with the resolved host.
Each time a request is handled by the daemon, it forks itself. This means that all child processes will share the same memory layout – including the addresses where modules are loaded. This simplified scenario is very common for many services such HTTP-proxies, email servers or DNS servers.
Exploitation Flow
For exploitation, we assume an attacker has the ability to answer arbitrary DNS requests performed by the server victim. The way this can be achieved is out of the scope of this paper; but, to name a few, this can be done by local ARP poisoning attack, DNS spoofing, etc.
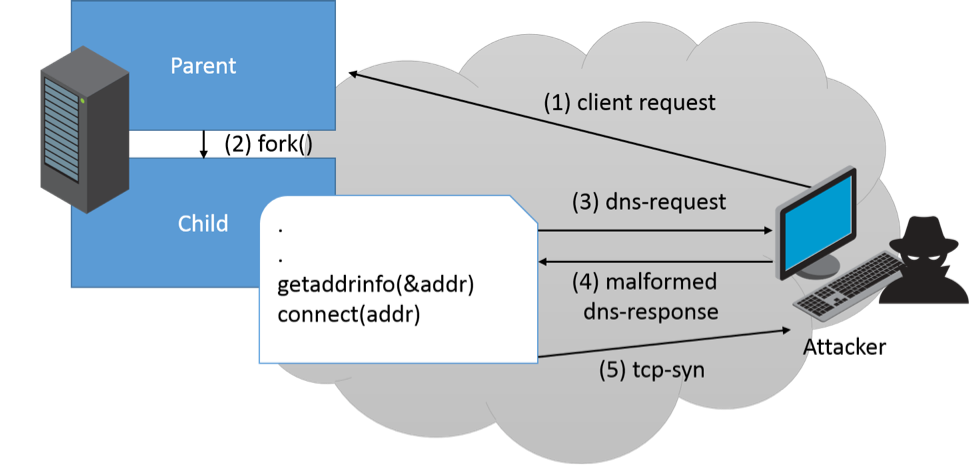
- An attacker initiates a request to the victim server.
- In order to handle the attacker’s request, the victim daemon forks itself.
- Forked child process performs a DNS request.
- Attacker replies with a malicious DNS response that overwrites the child process’ instruction pointer (RIP) to the address. In this example, it sets it to 0x12121212.
- Attacker gets a TCP-syn request initiated by the child process using “connect ()”.
If 0x12121212 is indeed the right return address of “getaddrinfo()”, then the application flow is continued as it should and issues the “connect()” right afterward.
|
1 2 |
0x000000001212120d call _getaddrinfo 0x0000000012121212 test eax, eax |
If this is not the situation, and the attacker transferred the instruction pointer (RIP) to any other address, the application will crash either due to a segmentation fault or invalid opcode execution.
|
1 2 3 4 |
0x0000000012121200 call _getaddrinfo 0x0000000012121206 test eax, eax .. 0x0000000012121212 invalid-opcode (RIP) |
This behavior can be used as an indication of whether an address is the correct return address of getaddrinfo (if so, a TCP-connection will be created). Since module addresses are not randomized between different forks(), this address remains constant in all child processes. An attacker can abuse this behavior and enumerate all possible addresses until guessed correctly. At each DNS-response, the adversary would reply with a different address, knowing a crash means that address is incorrect.
However, this still requires enumerating ~264, which is not feasible.
Byte-by-Byte Approach
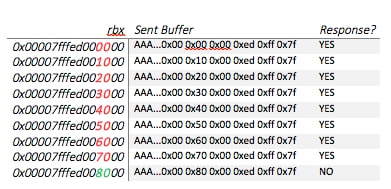
Instead, the attacker can overwrite a single byte every time. For example, assume the return address of getaddrinfo is 0x00007fff01020304:
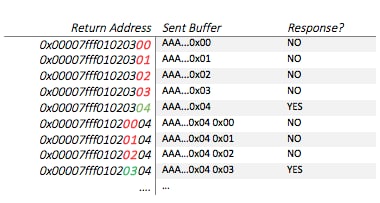
![]()
We first respond with the right amount of bytes that only overwrite the LSB of getaddrinfo’s return address. We overwrite it with 0x00, which is incorrect since, in the above example, the return address LSB is 0x04; getaddrinfo will return to 0x00007fff01020300, which is invalid, and will crash. We repeat this process, but each time we increase the guessed LSB by 1. When we reach 0x04, the application won’t crash – this means 0x04 is the LSB of the return address!
Now we repeat the entire process, enumerating the next byte by overwriting 2 bytes of the return address (0x04 0x00). We set the value of the first byte (LSB) to the previously leaked one, so we only enumerate the second. This is proceeded until the entire return address is leaked (each time enumerating the next byte).
With this approach, the maximum amount of tries is 8 * 28 tries (28 per byte, 8 bytes per address). This enumeration is quite small and feasible within a few seconds.
Finding Exploitable Applications
We used the website http://codesearch.debian.net, which indexes the source of ~18,000 Debian packages. Searching for all the applications that call both “fork()” and “getaddrinfo()”, we found over 1300 potential exploitable apps. We then need to inspect the source code of each app and check if its flow suits our needs.
Tinyproxy
The tinyproxy application matches this flow. A new child process is “fork()d” when it issues an HTTP-connect request. It then calls “getaddrinfo()” to retrieve the IP address of the requested website. Then “connect()”s that host to get the website content.
Exploitation
The diagram previously shown is a simplification of the actual scenario. When overwriting the return address, we also overwrite several stack variables. If the attacker doesn’t set those to the right values beforehand, the application will crash before returning from getaddrinfo. If that happens, the adversary will not be able to overwrite RIP. Thus the attacker would employ the same technique in order to leak them.
Leaking an Arbitrary Stack Pointer
The first crash we encountered happened to be on the following code block:
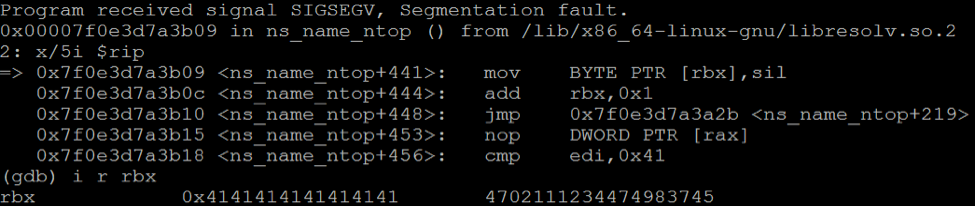
First, rbx gets overwritten. It is then dereferenced by the “mov BYTE PTR [rbx], sil” instruction. Originally, rbx pointed to a buffer on the stack. This means that, if we use the byte-by-byte approach, we can enumrate its value and leak an address on the stack.
The diagram below (output of /proc/PID/maps) shows the stack’s boundaries. As you can see, its initial size is always greater than 0x1000 bytes.
|
1 2 3 4 |
0x7ffd07882000 0x7ffd078a3000 0x21000 0x0 [stack] 0x7ffd079f0000 0x7ffd079f2000 0x2000 0x0 [vvar] 0x7ffd079f2000 0x7ffd079f4000 0x2000 0x0 [vdso] 0xffffffffff600000 0xffffffffff601000 0x1000 0x0 [vsyscall] |
The address pointed by rbx must be writable (otherwise a segmentation fault will be raised). But it happened to be a flaw in which it doesn’t matter to where we write the value of “sil”. As long as it is a writeable address, the flow will continue correctly. This means that it does not matter what value we set to the lower 12 bits of rbx since it will always be readable due to the size of the stack.
So we leaked an arbitrary pointer within the stack range. What happens when we have to be precise, where the address pointed by a stack variable affects the flow in a considerable way?
Leaking Stack Base
For situations like these, we have to rely on constant offsets. Since the flow of the application is always the same, the stack depth will always be the same. This means we can rely on the offset from stack base to these variables, structs and buffers.
Leaking the stack base is simpler than enumerating an arbitrary address. Since we already have an address within stack range – we can enumerate where the stack base is. We know the stack base is aligned to a page boundary (0x1000), and we also know that it will be the first non-readable address following the stack.
Let us assume that the stack base is at 0x00007fffed008000. We take the arbitrary stack address we leaked and align it to a page boundary – for instance 0x00007fffed000140 is aligned to 0x00007fffed000000. We then enumerate the stack base, starting from this aligned address and incrementing it between each attempt by 0x1000 (page size). After we send a response that overwrites the previously mentioned pointer, we wait for a short while and check if the server tried to connect to our resolved IP. If it did, it means we haven’t reached the stack base yet. If a timeout occurs, we assume the server crashed and we reached our goal.
Stack Base Offset
Before returning from getaddrinfo, the following check is performed:
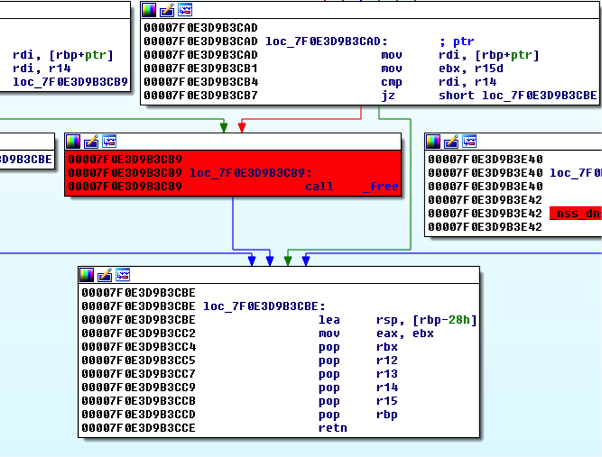
(@ glibc nss_dns_gethostbyname4_r)
Note the block that is highlighted in red. If we reach it and pass an invalid heap pointer as an argument, the application crashes (as it tries to free an invalid heap block). To bypass this free(), r14 and rdi must be equal. r14 points to the original __alloca() stack buffer. Since the stack base was previously leaked, and the __alloca() buffer’s offset from the stack base should be constant, we didn’t expect to encounter any problem. However, we found out that the offset is slightly different at every run. Why?
/arch/x86/kernel/process.c
|
1 2 3 4 5 6 |
unsigned long arch_align_stack(unsigned long sp) { if (!(current->personality & ADDR_NO_RANDOMIZE) && randomize_va_space) sp -= get_random_int() % 8192; return sp & ~0xf; } |
Observing the above kernel code, you can see that, if ASLR is enabled, SP (stack-pointer) is decremented by a random number. This means that there will be a random delta between rsp and the stack base on every different run.
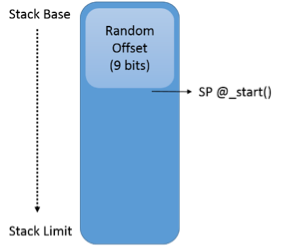
Fortunately, this number is quite small – only slightly bigger than the size of your average byte. We can easily enumerate this random offset.
Looking at the above IDA code snippet, we can see that if rdi equals to r14, the code path that attempts to free rdi won’t be taken. Thus, we used our previously leaked stack base, combined with a pre-calculated (i.e., if arch-align stack would return 0), and then attempted all the other 29 possibilities.
Leaking LIBC Module
This part is now trivial, as we use the previously mentioned technique to enumerate each byte of the return address.
Code Execution
All that is left to do is to construct a ROP chain. This is very easy and straightforward. We know the offset of system() function from the base of libc, so we just set up its argument and call it using ROP.
Conclusion
“Classic” stack overflow vulnerabilities do not provide address leaks by nature. Still, under certain conditions, an attacker can leverage creative techniques to exploit those vulnerabilities. In this research, we abused the way Linux creates processes to bypass ASLR. In other scenarios, different security mitigations might be evaded.
This technique can be leveraged for other memory corruption bugs. Therefore, a vigilant user should always attempt to secure servers by deploying software patches and updates in a timely fashion. At Palo Alto Networks, developing a deeper understanding of such exploitation methods is a core objective of our mission to help our clients prevent breaches and secure our way of life in the digital age. This type of knowledge allows us to develop better threat intelligence and implement preventive techniques that help our customers stay one step ahead of potential threat actors.
Related Blogs
Our library of online content is here to help you learn more, no matter what format you prefer or which topic interests you most.
Subscribe to the Newsletter!
Sign up to receive must-read articles, Playbooks of the Week, new feature announcements, and more.
By submitting this form, you agree to our Terms of Use and acknowledge our Privacy Statement. Please look for a confirmation email from us. If you don't receive it in the next 10 minutes, please check your spam folder.