
{kind=link}
AI, or artificial intelligence, is huge right now. “Unsolvable” problems are being solved, billions of dollars are being invested, and Microsoft even hired Common to tell you how great its AI is with spoken word poetry. Yikes.
As with any new technology, it can be hard to cut through the hype. I spent years doing research in robotics and UAVs and “AI,” but even I’ve had a hard time keeping up. In recent years I've spent a lot of time learning to answer even some of the most basic questions like:
- What are people talking about when they say AI?
- What’s the difference between AI, machine learning, and deep learning?
- What’s so great about deep learning?
- What kind of formerly hard problems are now easily solvable, and what’s still hard?
I know I’m not alone in wondering these things. So if you’ve been wondering what the AI excitement is all about at the most basic level, it's time for a little peek behind the curtain. If you’re an AI expert who reads NIPS papers for fun, there won’t be much new for you here—but we all look forward to your clarifications and corrections in the comments.
What is AI?
There’s an old joke in computer science that goes like this: what’s the difference between AI and automation? Well, automation is what we can do with computers, and AI is what we wish we could do. As soon as we figure out how to do something, it stops being AI and starts being automation.
That joke exists because, even today, AI isn’t well defined—artificial intelligence simply isn’t a technical term. If you were to look it up on Wikipedia, AI is “intelligence demonstrated by machines, in contrast to the natural intelligence displayed by humans and other animals.” That's about as vague as you can get.
Generally, there are two kinds of AI: strong AI and weak AI. Strong AI is what most people might be thinking of when they hear AI—some god-like omniscient intelligence like Skynet or Hal 9000 that's capable of general reasoning and human-like intelligence while surpassing human capabilities.
Weak AIs are highly specialized algorithms designed to answer specific, useful questions in narrowly defined problem domains. A really good chess-playing program, for example, fits this category. The same goes for software that’s really accurate in adjusting insurance premiums. These AI setups are impressive in their own way but very limited overall.
Hollywood aside, today we aren’t anywhere close to strong AI. Right now, all AI is weak AI, and most researchers in the field agree that the techniques we’ve come up with to make really great weak AIs probably won’t get us to Strong AI.
So AI currently represents more of a marketing term than a technical one. The reason companies are touting their “AIs” as opposed to “automation” is because they want to invoke the image of the Hollywood AIs in the public’s mind. But... that's not completely wrong. If we're being gracious, companies may simply be trying to say that, even though we’re nowhere near strong AI, the weak AIs of today are considerably more capable than those of only a few years ago.
Any marketing instincts aside, that’s actually true. In certain areas, in fact, there has been a steep change in capability in machines, and that’s largely because of the two other buzzwords you hear a lot: machine learning and deep learning.
Machine learning
Machine learning is a particular way of creating machine intelligence. Let’s say you wanted to launch a rocket and predict where it will go. This is, in the grand scheme of things, not that hard: gravity is pretty well understood and you can write down the equations and work out where it will go based on a few variables like speed and starting position.
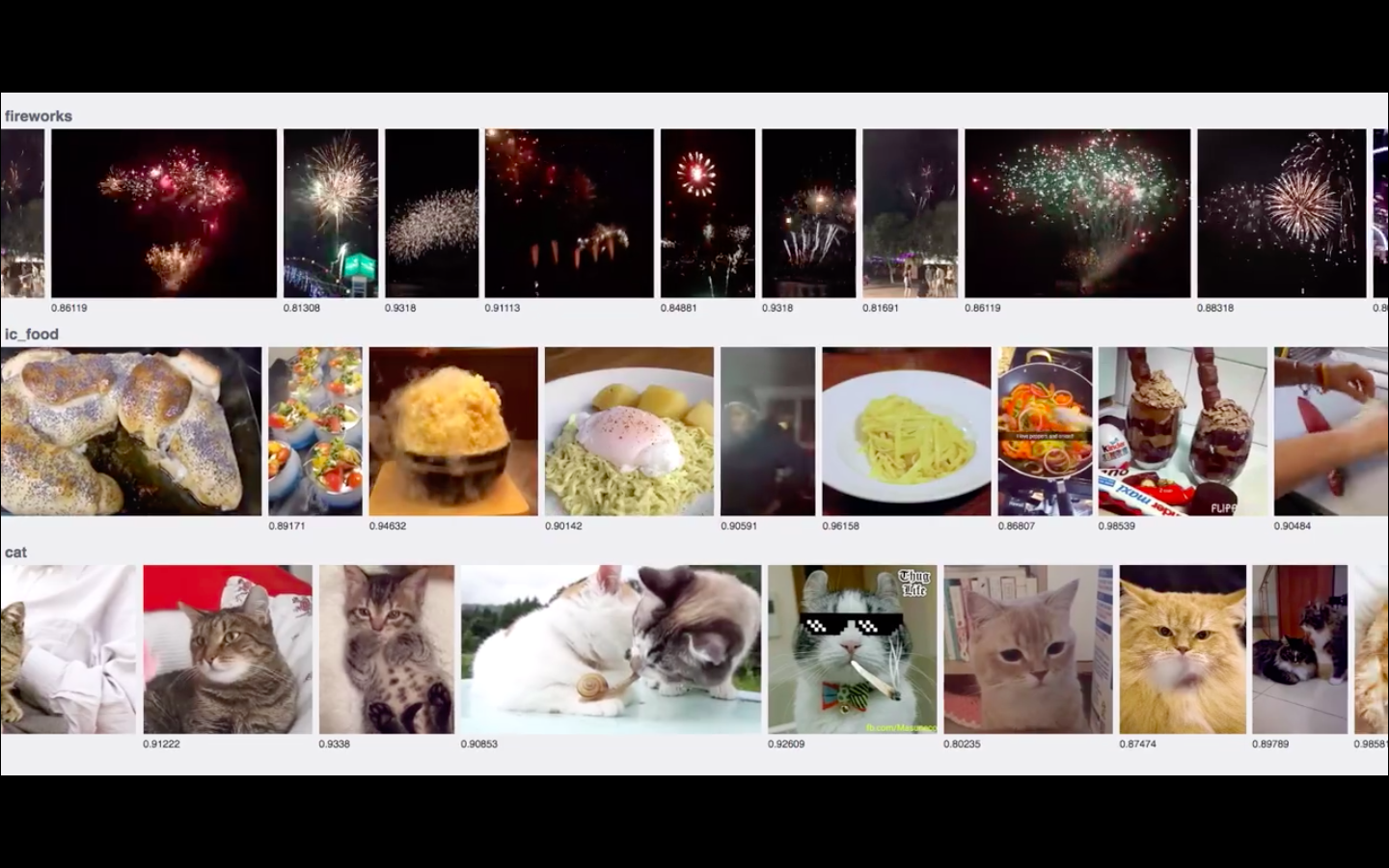
But this gets unwieldy when you’re looking at something where the rules aren’t as clear and well-known. Say you want a computer to look at pictures and you want to know if any of them shows a picture of a cat. How do you write down rules to describe what every possible combination of whiskers and cat ears looks like from every possible angle?
The machine learning approach is well-known by now: instead of trying to write down the rules, you build a system that can figure out its own set of internalized rules after being shown a lot of examples. Instead of trying to describe cats, you would just show your AI a lot of pictures of cats and let it figure out what is and is not a cat.
This is perfect for our present world. A system that learns its own rules from data can be improved by more data. And if there’s one thing we’ve gotten really good at as a species, it’s generating, storing, and managing a lot of data. Want to be better at recognizing cats? The Internet is generating millions of examples as we speak.
The ever-increasing tide of data is one part of why machine learning algorithms have been blowing up. The other part has to do with how to use the data.
With machine learning, besides the data there are two other, related questions:
- How do I remember what I’ve learned? On a computer, how do I store and represent the relationships and rules I’ve extracted from the example data?
- How do I do the learning? How do I modify the representation I’ve stored in response to new examples and get better?
In other words, what’s the thing that’s actually doing the learning from all this data?
In machine learning, the computational representation of the learning that you store is called the model. The kind of model you use has huge effects: it determines how your AI learns, what kind of data it can learn from, and what kind of questions you can ask of it.
Let’s take a look at a really simple example to see what I mean. Say we’re shopping for figs at the grocery store, and we want to make a machine learning AI that tells us when they’re ripe. This should be pretty easy, because with figs it’s basically the softer they are, the sweeter they are.
We could choose some samples of ripe and unripe fruits, see how sweet they are, then put them on a graph and fit a line. This line is our model.
-
Our baby AI, in line form. “The softer it is, the sweeter it is..."Haomiao Huang
-
Things quickly get more complicated when you add extra data, though.Haomiao Huang
Look at that! The line implicitly captures the idea of “the softer it is, the sweeter it is” without us having to write it down. Our baby AI doesn’t know anything about sugar content or how fruits ripen, but it can predict how sweet a fruit will be by squeezing it.
How do we train our model to make it better? We can collect some more samples and do another line fit to get more accurate predictions (as we did in the second image above).
Problems become immediately evident. We’ve been training our fig AI on nice grocery store figs so far, but what happens if we dump it in a fig orchard? All of a sudden, not only is there ripe fruit, there’s also rotten fruit. They’re super soft, but they’re definitely not good to eat.
What do we do? Well, it’s a machine learning model, so we can just feed it new data, right?
As the first image below shows, in this case we’d get a completely nonsense result. A line simply isn’t a good way to capture what happens when fruit gets too ripe. Our model no longer fits the underlying structure of the data.
Instead, we have to make a change and use a better, more complex model—maybe a parabola or something similar is a good fit. That tweak causes training to get more complicated, because fitting these curves requires more complicated math than fitting a line.
-
OK, maybe a line wasn't such a good idea for complex AI...Haomiao Huang
-
More complicated math now required.Haomiao Huang
This is a pretty silly example, but it shows you how the kind of model you choose determines the learning you can do. With figs, the data is simple so your models can be simple. But if you’re trying to learn something more complex, you need more complex models. Just as no amount of data would let the line-fit model capture how rotten fruit behaves, there’s no way to do a simple curve that fits to a pile of images and get a computer vision algorithm.
The challenge of machine learning, then, is in creating and choosing the right models for the right problems. We need a model that is sophisticated enough to capture really complicated relationships and structure but simple enough that we work with it and train it. So even though the Internet, smartphones, and so on have made tremendous amounts of data available to train on, we still need the right models to take advantage of this data.
And that's precisely where deep learning comes in.
reader comments
122