Life cycle monitoring for hybrid systems
Visibility, troubleshooting, and capacity planning and optimization
The metamorphosis of hybrid systems monitoring
Properly monitoring and improving your hybrid environment isn't a one-and-done activity—it’s an ongoing process
Life cycle monitoring for hybrid IT
Before you can solve problems or plan ahead, you need a visual inventory of your network and systems. The ability to see your environment in a single display, map your dependencies, and be alerted on potential issues with insights like predictive VM recommendations can open a whole new world of possibilities for your monitoring capabilities.

Comprehensive visibility
Oversee the health and performance of your physical and virtual servers—including hypervisors—whether you’re monitoring hybrid cloud, on-premises, hyperconverged, or cloud environments.
Identify complex performance issue
Set your monitoring environment up with over 1,200 out-of-the-box infrastructure and application monitoring templates.
Create unique views into your environment
Visibility to a SysAdmin means one thing, but it could mean something different to a DBA or the operations or application teams. Each person or department can build views specific to what they need using one platform and one source of truth.
All in the details
Provide granular visibility into the health of an application, down to the fans in the server the application runs on.
Troubleshooting hybrid IT systems
It doesn't matter how tightly you manage your IT environment; with change happening more frequently and ever-increasing complexity, things will happen, people will make errors, resources fine just yesterday will suddenly be strapped. Time isn’t your friend, and you can't afford to be wrong when identifying the root cause of issues.
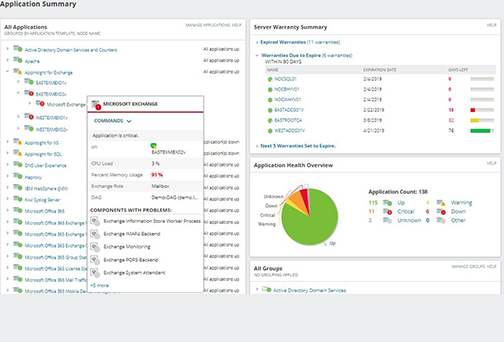
Optimization made easy
Combine metrics with VMware event logs to help identify and manage slow-running processes, services, logs, and scheduled tasks
Remove processes affecting server performance
Remote server monitoring designed to resolve problems with built-in server management actions: the Real-Time Process Explorer identifies resource hogs
Identify your dependencies
A historical account of configuration data and infrastructure relationships helps you identify what dependencies existed at a specific time, such as VMs belonging to a host seven days ago.
Find out “what changed” sooner rather than later
Gain the ability to visualize and monitor syslog messages, SNMP traps, or Windows event logs in real time for the near-instantaneous insights you need for effective troubleshooting.
Capacity planning and optimization
At its core, capacity planning and optimization involve monitoring and alerting on physical or virtual server resources, such as CPU, memory, disk, and network. Forecasting when your server will run out of resources is essential to help you optimize your current and future infrastructure investments. SolarWinds hybrid systems monitoring provides capacity planning tools designed to simplify capacity planning and help you optimize resources you use to support your present and future hybrid infrastructure needs.

Server and hardware resource investments
Built-in forecast charts and metrics help you identify when physical or virtual server resources reach warning and critical thresholds.
Optimize performance more efficiently
Quickly see what's causing server resource contention by tracking how much CPU, memory, and storage is being consumed, allowing you to quickly find and delete processes consuming excess memory.
Scalability when the time is right
Gain access to a modeling function designed to project future server and hardware additions to see if your environment can scale to meet workload needs.
Plan for future workload placement
Gain access to a Hyper-V capacity planning function to determine the best location for virtual machines.
Life cycle monitoring for today’s hybrid IT systems environments
To dive deeper and learn even more about these hybrid systems monitoring topics, gain insightful thought leadership from SolarWinds Head Geeks™, and see the products in practice via demo, watch the three-part webcast series on visibility, troubleshooting, capacity planning, and optimization available on-demand.

Experience yields insights. Here's some of what we've learned.

Communications service provider saves millions
This customer saved more than $2 million in recurring annual costs after replacing several disparate monitoring tools with Hybrid Cloud Observability.

Enterprise cloud operations team gains 5x ROI over three years
The popular retailer achieved these savings by retiring an array of open-source tools and problematic SaaS-based IT monitoring tools.

SolarWinds is a trusted leader, year after year
SolarWinds was recognized in the GigaOm Radar reports as a Leader in Network and Cloud Observability.
You may still have questions.
We have answers.