Why the World's Most Perfect News Tweet Is Kind of Boring
Researchers have found a way to predict a news story's popularity -- with an astounding 84 percent accuracy.
![[optional image description]](https://cdn.theatlantic.com/media/mt/science/twit_halo.png)
Here, per one algorithm, could be the Platonic version of the news tweet:
Bits Blog: Apple Buddies Up With Cheaper Wireless Partners for iPhone nyti.ms/LcLviE
-- The New York Times (@nytimes) June 8, 2012
If that seems a little dull for Twitter Perfection ... well, that's the point. Steadiness -- compelling news expressed in straightforward, not hyperbolic, language -- is actually a component of maximally shareable content, the algorithm suggests. And this particular tweet is also sent from a credible source, The New York Times, which makes it extra-spreadable. It's about technology, the most popular, shareable category of news story. It's engaging without being insistent. And it stars a company -- Apple -- with high name recognition.
The algorithm comes courtesy of a fascinating paper [pdf] from UCLA and Hewlett-Packard's HP Labs. The researchers Roja Bandari, Sitram Asur, and Bernardo Huberman teamed up to try to predict the popularity -- which is to say, the spreadability -- of news articles in the social space. While previous work has relied on articles' early performance to predict their popularity over their remaining lifespan, Bandari et al focused on predicting their popularity even before they're formulated in the first place. The researchers have developed a tool that allows people -- and, in particular, news organizations -- to calibrate their content in advance of their posting and tweeting, creating stuff that's optimized for maximum attention and impact. That tool allows for the forecasting of an article's popularity with a remarkable 84 percent accuracy -- and it has implications not just for articles, but for tweets themselves.
To develop their algorithm, the researchers hypothesized that four factors would determine an article's social success:
- The news source that creates and publishes the article
- The category of news the article belongs to (technology, health, sports)
- Whether the language in the article was emotional or objective
- Whether celebrities, famous brands, or other notable institutions are mentioned
The team then used publicly available tools like Feedzilla's API to gather a dataset of over 40,000 news articles, collected during a nine-day span in August 2011. They used Feedzilla's topic metadata to assign a category to each article (distinguishing among, say, tech stories, business stories, sports stories, and the like). And they used Stanford's Named Entity Recognizer to identify text representing a famous person or company name -- Lady Gaga, say -- and to measure the prominence of that name relative to others. What resulted was a score for each of those 40,000 articles based on the team's four factors.
The team then compared the number of retweets and shares each news article garnered over time, using the Twitter search engine Topsy. Their key metric was what they termed t-density, or the number of tweets earned by each news link.
Here are their findings, broken down by news category:
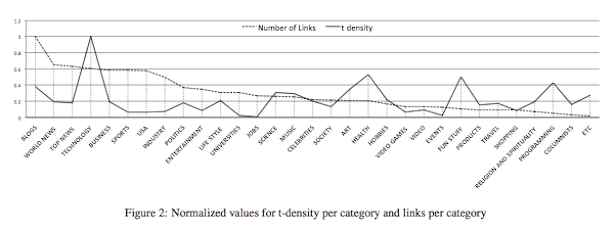
As the graph makes clear, the category of news involved in the article certainly made a difference to a tweeted story's popularity: Technology was the most tweetable news area, followed by Health and the ever-shareable Fun Stuff. Also impactful was the name recognition of the text. You can know with some certainty that a story about Lady Gaga will do well, and you can know with even more certainty that a tech story about Lady Gaga will do well. But what led most overwhelmingly, and most predictably, to sharing was the person or organization who shared the information in the first place -- hence, the @NYTimes origin of the tweet above. A "WHOA, GUYS, HERE'S HUGE NEWS ABOUT LADY GAGA" sent from The New York Times means a lot more than the same declaration from me, or even from @LadyGaga herself. Brand, even and especially on the Internet, matters.
Furthermore, emotional language doesn't seem to matter when it comes to predictable sharing. So, by that logic, a tweet that calmly describes what you'll get by clicking on a link -- "Here is some news about Lady Gaga" -- will have about the same attentional impact as a tweet that HYPERBOLICALLY SHOUTS IT. Even within the tumult that is the Internet, when it comes to framing the news, objective language does just as well as emotional.
While that's unsurprising on the one hand, on the other it's its own kind of WHOA HUGE NEWS finding. Conventional wisdom -- and even our everyday experience of the web -- might suggest that emotion and overall WHOAness would trump other considerations. This is the operational logic of a site like Buzzfeed, whose brand is driven by little else beyond the WHOA. And Twitter, in particular, has a flattening effect: Our rolling, rollicking sources of news all roll and rollick within the same 140-character-high little boxes. On Twitter, puny little @megangarber gets the same physical real estate as @WSJ, @NYTimes, and @BarackObama. (And if puny little @megangarber posts a lot of tweets, she'd get, actually, more physical real estate than the established institutions.)
In that context, it would stand to reason that the words and the resonance of the tweets themselves -- the content of the characters -- would make the real difference between "share" and "ignore."
What's remarkable about the HP paper and its algorithm is how back-to-the-future their results actually are. Online, the researchers are saying, the power of the brand is exactly what it has been since brands first emerged in the Middle Ages: It's a vector of trust. And it's a direct proxy for the ongoing transactional realities of the in-person human relationship. While Twitter and its fellow social media platforms certainly allow for breakthrough, source-agnostic WHOAs -- @keithurbahn, Double Rainbow Guy -- the HP study suggests that, when it comes to news, trust is actually much more important than emotion. Shareability is largely a function of reliability.
That makes sense, given that we users are increasingly aware of ourselves not only as conduits of information, but as agents of it. Though I will eagerly click on a "WHOA, THIS IS HUGE" link from someone I follow, I'm much more likely to share a WTIH link when it's sent by @NYTimes. I don't want to be amplifying bad intel. And I understand, implicitly, that something sent from the Times -- something vetted by an organization that has a lot to lose in getting something wrong -- is more trustworthy than something sent from another person. Even if that person is a friend.
This is a the probabilistic brand in action. Though it's easy (and sometimes accurate) to think that the web is fracturing once-solid institutions ... on Twitter, at least, the opposite seems to be true. On Twitter, the brand -- a convening force, an agent of trust, an assurance of quality -- is more valuable than ever.
The HP paper focuses on article popularity, with Twitter spread as the key metric of that popularity. The original wording of this post wasn't clear about that, so I've updated the language above to better reflect the distinction. And big thanks to Steve Myers for pointing it out.