Dáša Kunstová, Peťa Macháčková a Áňa Walterová: Analýzou ke zvýšení prodeje krmiv
Historický vznik
Dáša s Peťou utvořily dvojici ve chvíli, kdy zazněla otázka od Lenky: "Máte dvojici?".
Áňa byla po odhlášení jedné z účastnic lichá a téma projektu holek se ji zamlouvalo. A bylo :)
1. Počátek
Když jsme si vybíraly téma projektu, neměly jsme moc představu o tom, co se dokážeme během akademie naučit a co zvládneme. Měly jsme ale jasno v tom, že chceme, aby projekt nesloužil jen k otestování našich dovedností. Proto jsme oslovily naše přátele, jestli by pro nás neměli nějaký úkol, který by se týkal datové analytiky, a před prvním setkáním s mentory jsme měly tři možná témata, ze kterých nakonec vykrystalizovala analýza prodeje e-shopu.E-shop se zabývá prodejem prémiových značek krmiv pro psy a kočky, nenabízí nic jiného. Funguje od roku 2015 a jedná se o malý obchod přibližně s osmdesáti prodeji za měsíc. Majitel investoval do reklamy na začátku podnikání, ale nyní už žádná reklamní kampaň neprobíhá.
Cílem našeho projektu je zmapovat data o prodejích a zákaznících a na základě toho dát majiteli informace, které by pomohly zefektivnit jeho prodeje. Co přesně lze v datech nalézt nebylo dopředu známé, majitel e-shopu je neměl u sebe, musel si je vyžádat u správce databáze.
Technologie a nástroje které jsme plánovaly v projektu použít, byly: SQL pro vyčištění a prvotní seznámení s daty, Power BI pro jejich vizualizaci a Python pro pravidelné automatické tvoření reportů i po skončení práce na projektu.
2. Realizace
Po Meet Your Mentor, kdy už bylo jasné, na kterém tématu budeme pracovat, už zbývalo získat to hlavní - data. Ty jsme obdržely dva dny před Hackathonem. Po letmém zhlédnutí dat jsme kontaktovaly našeho mentora Miloše Minaříka a odpověděly si na pár otázek, co bychom z dat chtěly získat. Data obsahovala pět tabulek ve formě csv souborů. Byla ve špatném stavu - rozházené hodnoty, v každé tabulce se kategorie jmenovala jinak atd. Nebylo jich ale mnoho, tudíž se nad daty nedalo provádět mnoho statistiky a zaměřily jsme se tedy spíš na kvalitativní analýzu a konkrétní zajímavé případy.Přestože v csv souborech nebylo extrémní množství dat, trvalo nám velmi dlouho, než jsme je očistily. Opravdu jsme netušily, že nám čištění dat zabere 80% času Hackathonu. K čištění dat jsme používaly Excel i SQL.
Pak jsme se začaly na data poprvé dívat skrz databázi a MS SQL. Po odhalení dalších chyb jsme pak čistá data nahrály do Power BI, sestavily první set otázek, které nás na datech zajímaly, a začaly získávat odpovědi. Okamžikem přesunutí se do Power BI se náš tým rozdělil na dvě části - jedna zkoumala data a druhá programovala kód v Pythonu, který by je uměl vytáhnout z databáze, uložit do souboru nebo z nich udělat graf, který by byl přínosný pro majitele e-shopu. Ten má velmi omezený přístup k databázi (přes správce), takže jediné informace, které o obchodu má, jsou z účetních tabulek. Na konci Hackathonu jsme měly relativně čistá data, zodpovězené některé otázky a program v Pythonu, který se dokázal napojit na databázi a vypsat Top 5 největších zákazníků.
Další týdny po Hackathonu jsme znovu procházely data v Power BI a při analýze podle místa objednatele jsme narazily na nesoulad s porovnávanými údaji – někde nám chyběla PSČ a jinde města. Takže pokud bychom chtěly třídit zákazníky podle místa, nebudeme mít kompletní údaje. Bylo se tedy nutné vrátit na úplný začátek, do databáze doplnit chybějící informace a nahrát do tabulky znovu data s kompletními údaji. Tuto záležitost jsme nahrály přes Power BI pomocí Power Query, bylo nutné odstranit duplicity v PSČ, aby mohla být použita vazba s ostatními tabulkami.
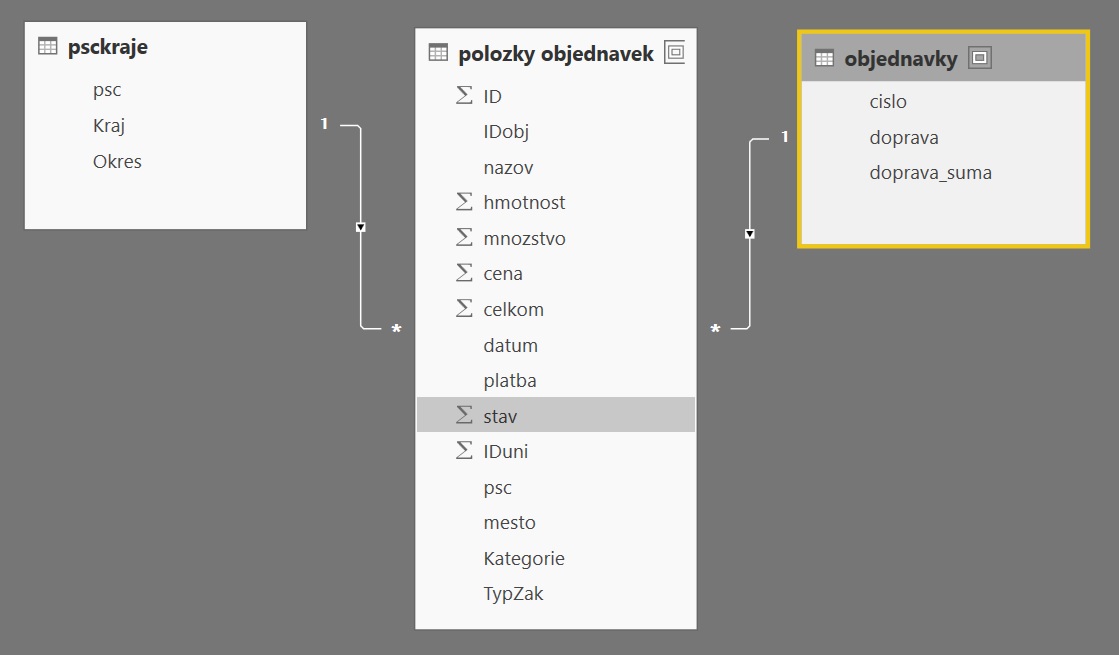
3. Prezentace výsledků
Co jsme v Power BI například zjistily?
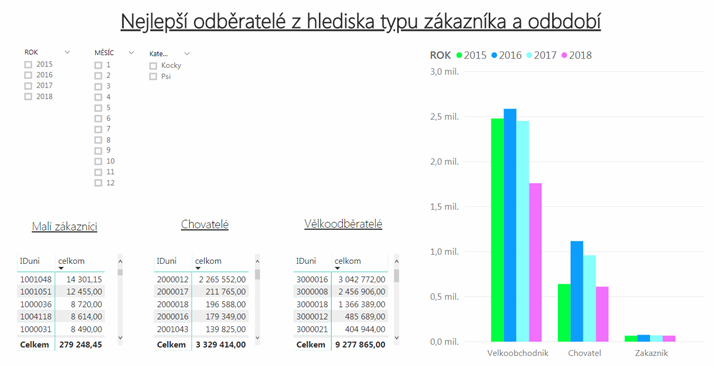
1) Největší podíl na tržbách e-shopu v letech 2015 – 2018 mají 4 velkoobchodníci, kteří tvoří více jak 70% všech tržeb.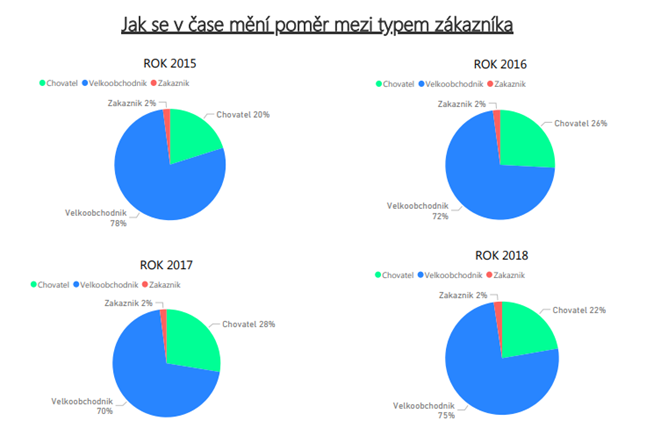
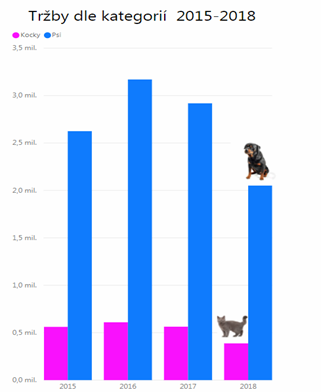
3) Mezi nejprodávanější krmiva pro kočky v letech 2015 - 2018 patřila bezlepková krmiva a krmiva pro dospělé kočky, mezi nejprodávanější krmiva pro psy to byla krmiva pro velká psí plemena, pro malá plemena a bezlepková krmiva.
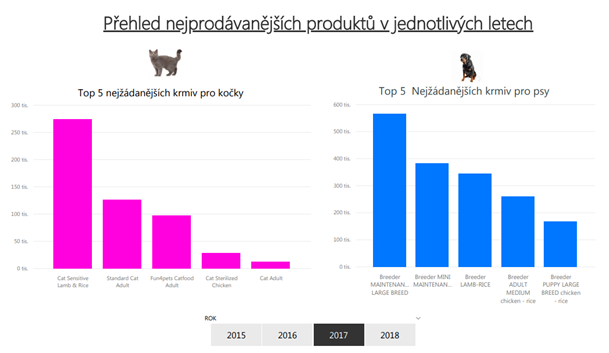
4) Odkud vlastně jsou největší odběratelé z hlediska krajů a okresů s největším podílem tržeb?
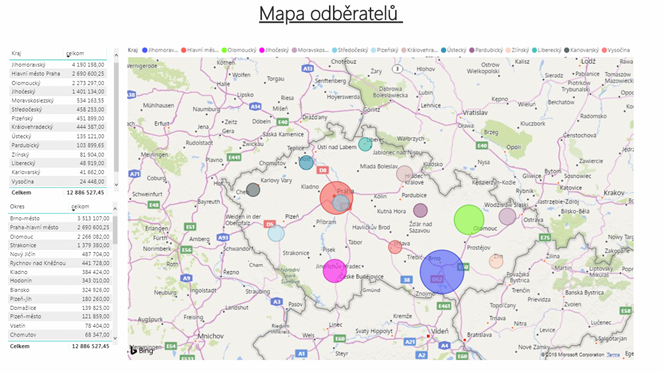
Co jsme zjistily pomocí SQL:
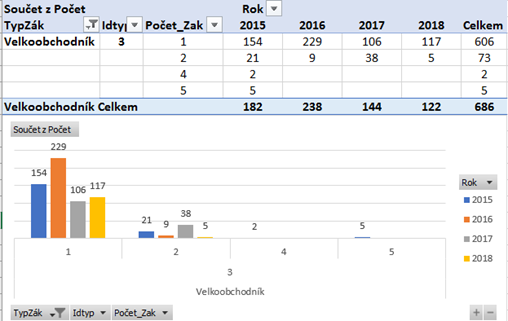
1) Počet menších zákazníků během let 2015-2017 měl vzestupnou tendenci, chovatelé jsou během uvedených let zhruba na stejné úrovni, ale nejvíce nás zajímají velkoobchodníci, kteří se podílí na tržbách ve více než 70%. Velkoobchodníci z hlediska počtu objednávek bohužel během let 2015-2017 mají klesající tendenci.

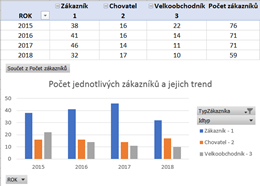
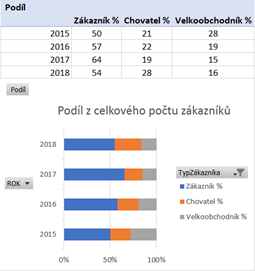
2) Jaké množství objednávek bylo vyhotoveno jakým množstvím jednotlivých zákazníků?
Z hlediska menších zákazníků je viditelné, že největší počet zákazníků si objednalo pouze jedenkrát a to např. 31 zákazníků v roce 2017 má jen jednu objednávku a 27 zákazníků v roce 2016 má také jen jednu objednávku v období let 2015-2018.Z hlediska chovatelů je již situace trochu jiná, kdy jedním chovatelem bylo učiněno 487 objednávek v období let 2015-2018.
Z hlediska velkoobchodníků je zřetelné, že většina objednávek v celkovém množství 606 v období 2015-2018 byla učiněna jedním velkoobchodníkem.


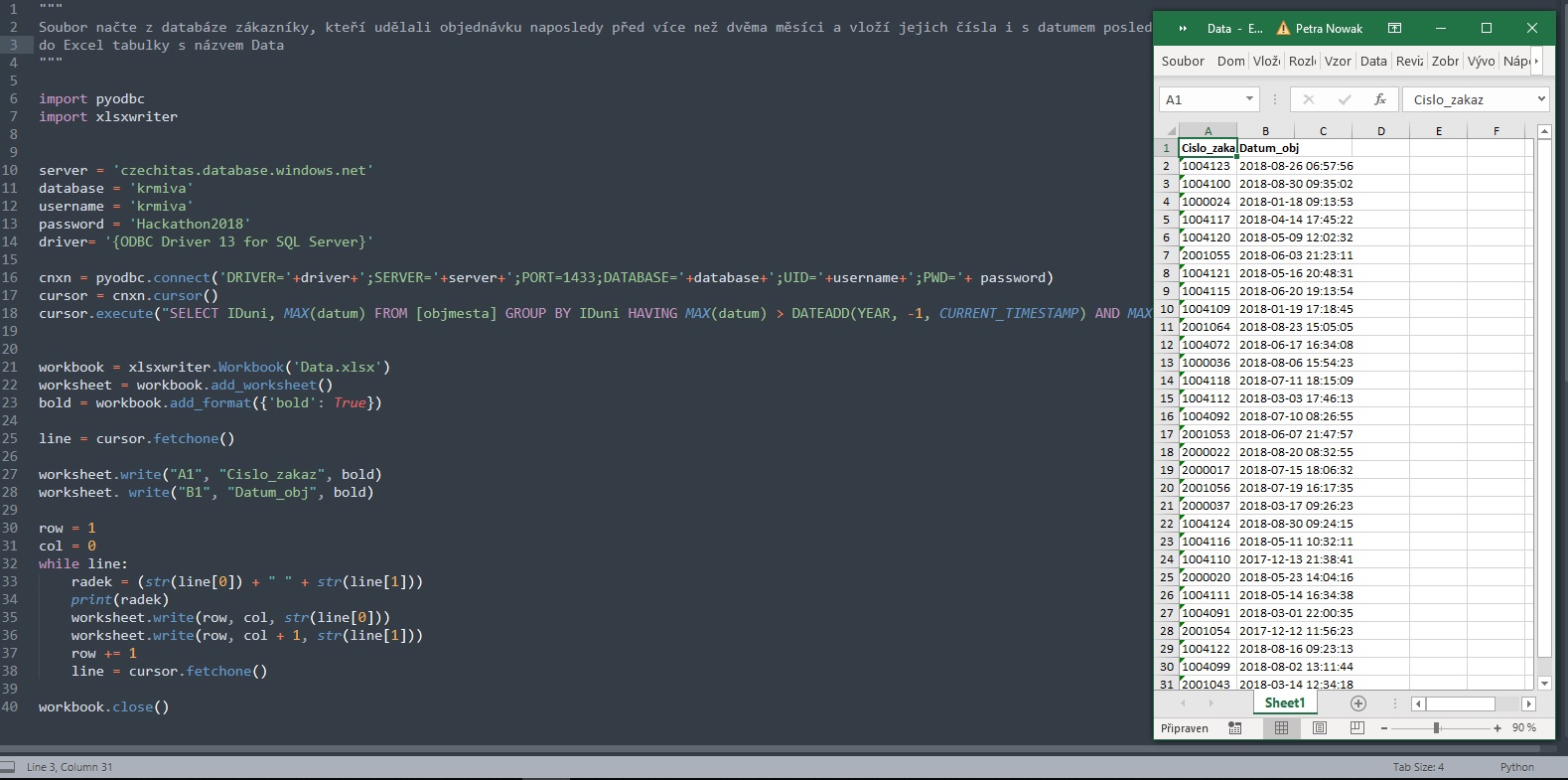
Programování v Pythonu
Protože majitel e-shopu nemá okamžitý přístup do databáze, kam se ukládají objednávky a registrovaní zákazníci, napadlo nás, že bychom mu mohly vytvořit program v Pythonu, který by mu dokázal z databáze pravidelně vytahovat informace, aby měl přehled o prodejích kdykoliv bude chtít. Velký díl kódu jsme vytvořily během Hackathonu. Nejvíce práce způsobilo přepisování dat do csv souboru, protože pořád vypisoval požadovaná data s čárkami navíc. Chybu jsme nakonec odhalily a opravily, ale soubor jsme nakonec k ničemu nevyužily. S csv soubory umí málokdo pracovat, takže jsme se rozhodly nechat program data z databáze zapsat do Excel tabulky.Během data miningu jsme narazily na to, že průměrná prodleva mezi objednávkami je dva měsíce, takže jsme se místo toho rozhodly vytvořit program, vypisující zákazníky, kteří si objednali před dvěma a více měsíci (ale ne víc, jak před rokem) a datum jejich poslední objednávky, aby jim mohl prodejce poslat nabídku pro další objednávku.
Mimo to jsme ještě dostaly příležitost vytvořit soubor s příponou .arff pro zpracování dat pomocí machine learning a Weky, protože Miloš je na machine learning odborník a napadlo ho, že bychom se mohli zkusit podívat na data o zákaznících a jejich objednávkách i s jeho pomocí.


4. Přínosy a možná rozšíření projektu:
Projekt nám přinesl opravdu hodně nového a během práce s daty jsme si prakticky vyzkoušely většinu dovedností, které jsme získávaly na Digitální akademii. Když začneme od začátku, tak MS Excel při prvotním prohlížení a upravování dat, SQL pro hlubší náhledy a čištění dat, Power BI pro vizualizaci zjištěných skutečností a v neposlední řadě Python pro získání dat z databáze a jejich následné použití při machine learningu. Pevně věříme, že to, co jsme zjistily, pomůže majiteli e-shopu zefektivnit nabídku a zvýšit klesající prodeje. Pokud bude mít zájem o další spolupráci, můžeme mu pomoci s upravením databáze, nastavením správného datového modelu a zautomatizovat přehledy o objednávkách a zákaznících.Pár doporučení pro majitele e-shopu:
V prvé řadě umístit reklamu do míst, kde to dává smysl. Předně do větších měst, kde už e-shop nějakým způsobem funguje, ale má nevyužitý potenciál (např. Pardubice pouze 4 zákazníci, Plzeň 46, Ostrava 25, Liberec 10, Teplice 9, Zlín 4). Nicméně není na škodu podpořit i města, ve kterých by jich mohlo být nepoměrně více - např. Brno 1044. Druhé zajímavé doporučení vzešlo ze skriptu v Pythonu, díky kterému jsme zaznamenali delší neaktivitu pravidelných zákazníků. V takovém případě může majitel rozeslat e-maily s dotazníky (ne)spokojenosti nebo popřípadě nabídnout slevu. Neškodný mail by šel poslat i odběratelům, kteří nakupují s určitou pravidelností. Vypadalo by to tak, že zhruba čtrnáct dní před blížícím se pomyslným pravidelným nákupem by se poslal mail připomínající nákup. Třetí doporučení se týká vybraných krmiv pro kočky. Samotná krmiva pro kočky obecně pokulhávají a některé produkty bychom pro extrémně malý úspěch stáhli z prodeje. Do čtvrtice všeho dobrého jsme odhalily, že obchod prakticky stojí na čtyřech velkoobchodnících, jednom zákazníkovi a jednom chovateli. Ty by nebylo dobré ztratit, tudíž by si je občas mohl předcházet nějakou tou slevou. Zároveň by chtělo rozšířit počet pravidelně nakupujících zákazníků, aby ho případná ztráta “velké ryby” nepoložila.5. Závěr a poděkování:
Když jsme před dvěma měsíci začaly pracovat na našem projektu, vůbec jsme nevěděly, co vše zvládneme, co nás čeká. Téma datové analýzy e-shopu s krmivy pro domácí zvířata asi nemusí každému znít moc zajímavě, ale jak se ukázalo, hledání odpovědí, procházení dat a nacházení různých skrytých souvislostí, to bylo opravdové dobrodružství. Naučily jsme se pracovat s nástroji pro datovou analýzu, použily jsme vědomosti získané na seminářích Excelu, SQL, Power BI nebo Pythonu, procvičily jsme si hledání na Googlu, ale to není vše. Prožily jsme opravdu nezapomenutelné chvíle, třeba kdy nám vzdorovalo Power BI a nechtělo nám ukázat to, co jsme chtěly, zoufalství ve chvíli, kdy jsme zjistily, že data ještě opravdu nejsou čistá (několikrát), nekonečnou frustraci z toho, že ten kód v Pythonu nefunguje a objevují se hlášky typu "programming error", ale také tu radost, když jsme vytvořily první pěkný graf, tu obrovskou úlevu a radost z objevení chyby (chybějící "zobáček" >), to nadšení z informací, které jsme z dat dokázaly vyčíst. To všechno je součástí práce datových analytiků a je skvělé, že jsme si to mohly v rámci projektu vyzkoušet, takže nebudeme ve své budoucí práci překvapené. Na závěr bychom chtěly moc poděkovat našemu skvělému mentorovi Miloši Minaříkovi za péči a trpělivost. Nebýt jeho vedení, tak náš projekt není zdaleka tak dobrý. Dále děkujeme za pomoc i rady dalším mentorům a lektorům z kurzu, Adéle Krátké, Katce Brabcové. Ani bez nich bychom to nezvládly. V neposlední řadě ještě děkujeme našim partnerům a rodinám, bez jejichž podpory bychom se neobešly.6. Informační zdroje:
Připojení Pythonu na databázi
https://docs.microsoft.com/en-us/sql/relational-databases/tables/specify-computed-columns-in-a-table?view=sql-server-2017
https://docs.microsoft.com/cs-cz/azure/sql-database/sql-database-connect-query-python
Zápis dat v Pythonu do Excellu pomocí knihovny XlsxWriter:
https://xlsxwriter.readthedocs.io/


Já už se hrozně těším, až si budu dělat takové analýzy, grafy a porovnávat jednotlivé měsíce. Vím, že bude každý jiný, každý den je jiný, ale něco se z toho bude dát určitě vyčíst a najít třeba chybu, kterou budu dělat. zas tak si nevěřím, že bude všechno pořád na 100%, i když se o to budu samozřejmě snažit :-) . Založení s.r.o. pro mě bylo velkým krokem, ale nelituji toho. Naopak jsem ráda, že jsem ten velký krok konečně udělala :-) .
OdpovědětVymazat