

Un titre facile à trouver pour une réponse qui ne l’est pas moins : à peu près tout le monde. Et bonne nouvelle pour tous ceux qui n’avaient rien compris aux offres de Data Governance, voici venu le temps du Data Catalog, qui remet, comme on dit, l’église au centre du village. Car, autre bonne nouvelle, le Data Catalog apporte aussi une réponse à l’évolution des principes d’Architecture d’Entreprise (EA) à l’ère du Digital.
A quoi ça sert ?
Ni plus ni moins qu’à construire un dictionnaire des données de l’entreprise, dans l’idée de décrire le métier par les données, en s’appuyant sur les sources de données présentes et non sur des constructions théoriques. Ce besoin a vu le jour avec la multiplication des sources de données et particulièrement les configurations Big Data ou les Data Lakes.
Cela fait quelques années qu’on se demande comment on va pouvoir continuer à modéliser les données dans des solutions d’Architecture d’Entreprise qui n’ont pas su évoluer avec leur temps.
Chez Astrakhan, nous nous sommes d’abord tournés vers des solutions de nouvelle génération, comme Ardoq et BizzDesign qui restent, pour la modélisation générale, des choix dont nous sommes profondément convaincus.
Ceci étant, la Data continuant de prendre une place de plus en plus importante dans le paysage, il était inévitable que des solutions dédiées à sa modélisation voient le jour.
Une Architecture d’Entreprise orientée Données
L’émergence depuis 18 mois des Data Catalog est le signe positif que la pratique de l’Architecture d’Entreprise continue de se renouveler. Pourquoi ?
1. Parce que Data Catalog rime (presque) avec Metadata Management. C’est le vrai sujet : la gestion des méta-données, l’élaboration d’un modèle sémantique d’entreprise, d’un glossaire métier d’entreprise, d’une architecture de données, bref tout ce que l’on recherche traditionnellement dans l’EA.
2. Parce que toutes les sources de données sont concernées : internes, externes (Open), structurées, non structurées, au repos ou en mouvement, et quelles que soient leurs sources, relationnelles, NoSQL, Big Data, Data Lake… et demain, probablement, Blockchains.
3. Parce que les solutions de Data Catalog rapprochent la modélisation de l’exécution, et vice-versa (on parle par exemple de curation de données multi-sources), ce qui est une caractéristique forte de ce que l’on est en droit d’attendre de solutions d’EA modernes.
4. Parce qu’il s’agit d’aller vers le Good Data en améliorant la qualité de la donnée, sa documentation, sa gouvernance, autant d’objectifs et de fonctionnalités que l’on apparente assez facilement à ceux des solutions d’EA.
Un marché remodelé
En préambule, nous avons affirmé que les offres de Data Catalog allaient faire prendre un petit coup de vieux aux offres de Data Governance. C’est déjà le cas.
La majorité des solutions de Data Catalog sont dotées de fonctionnalités de Lineage, qui jusqu’à présent étaient le propre des solutions de Data Governance, et de Data Quality. Qui plus est, la concurrence entre ces offres est renforcée par l’arrivée d’acteurs disposant de logiques de plate-forme, comme Informatica ou Microsoft, qui insistent fortement sur leur Data Catalog.
On constate aussi que sur ce marché plus large du Metadata Management, les acteurs ont tendance à se bousculer, ce qui est bon signe. Sur celui de la Data Governance en revanche, on en dénombre moins. Et par conséquent, on n’est que modérément surpris de voir des acteurs comme Collibra se positionner sur le Data Catalog.
Un modèle fonctionnel hybride
Le schéma suivant propose une lecture des fonctionnalités généralement attribuées aux outils de Data Catalog. On y trouve la Collaboration, mise en avant par des acteurs comme Alation. Une fonctionnalité indispensable puisqu’il va s’agir ici de faire collaborer des rôles aussi variés que des Business Analysts, des Data Stewards et des experts de domaine.
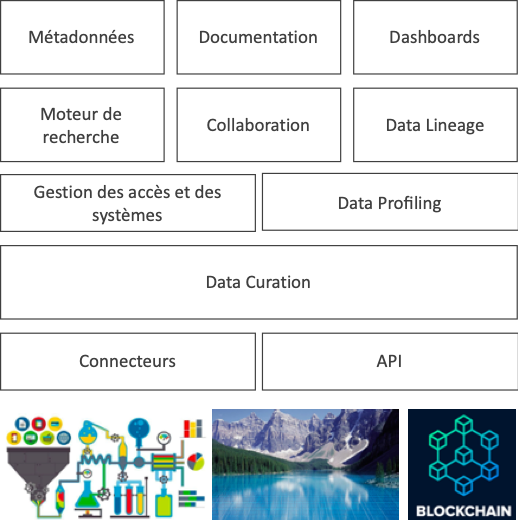
D’autres, comme Ataccama, mettent en avant l’introduction de fonctionnalités apprenantes (machine learning), qui accélèrent la mise en place de la solution dès que celle-ci a compris, par l’observation du travail des premiers utilisateurs, comment travailler. Ces solutions sont aussi amenées à se positionner dans un environnement plus large, ouvert aux APIs.
Néanmoins, l’existence de certaines de ces fonctionnalités dans d’autres types de solution pour lesquelles l’entreprise a déjà pu investir par le passé (Data Governance, Data Virtualization, Data Quality…), montre qu’en la matière, et même si tout le monde est concerné, un inventaire de l’existant doublé de l’identification des cas d’usage à couvrir constituera un pré-requis à tout investissement.
