
In March of this year, a massive grave was uncovered buried beneath the soil of the coastal Mexican state of Veracruz. The grave made national headlines because it contained more than 240 skulls and corpses, the remains of disappeared people (link in Spanish).
But for many, the grave’s existence came as no surprise. In Mexico, a country where almost 30,000 people have gone missing due to drug-related violence since 2006, the grave was a reminder of a difficult reality: the search for missing people often begins by looking underground.
Mexico is home to over 122 million people and spans more than 750,000 square miles of land. There is no road map that makes clear where to start the search for mass graves, or the bodies of the disappeared (desaparecidos) that they hold.
Or at least there hasn’t been—until now. A team of multi-country researchers, data scientists, and statisticians is using machine learning to predict which counties in Mexico are most likely to have hidden graves. If their model works as well as they hope, it will be a powerful application of an emerging technology that provide answers to one of the most difficult aspects of the desaparecidos problem: knowing where to look.
The team is composed of three separate groups: the Programa de Derechos Humanos at the Ibero-American University in Mexico City; data-focused non-profit Data Cívica, also based in Mexico City; and the Human Rights Data Analysis Group (HRDAG), a San Francisco-based organization that applies scientific analysis to human rights violations (first two links in Spanish).

Each organization contributes a unique piece of analysis or data which together form a fuller picture of where to search. The group at the Ibero-American University has been scraping local and national Mexican newspaper and radio data for mentions of hidden graves for years as part of a larger project. They’ve created a comprehensive database of the details behind every report of a hidden grave. It’s the country’s first database of the sort, and it’s a crucial bank of knowledge that details in which municipalities hidden graves have been discovered in the past.
Data Cívica contributes data on social demographics about every municipio, or county, in the country. By combining Mexico’s public open data system with geographic data, they’ve been able to create a detailed profile of sociodemographic data for every one of Mexico’s 2457 counties.
These two pieces are crucial to the machine learning model that HRDAG uses to predict which counties are likely to have hidden graves in them. The model is called a Random Forest classifier, and its usefulness hinges on the idea that there is something categorically different between counties that have historically been found to have hidden graves, and those that have not. The model sorts through the characteristics and weights their relevance. It then becomes possible to predict, based on those characteristics, which counties are most likely to have graves found in them in the future.

Patrick Ball, HRDAG’s Director of Research and the statistician behind the code, explained that the Random Forest classifier was able to predict with 100% accuracy which counties that would go on to have mass graves found in them in 2014 by using the model against data from 2013. The model also predicted the counties that did not have mass hidden graves found in them, but that show a high likelihood of the possibility. This prediction aspect of the model is the part that holds the most potential for future research.
Ball was quick to add, “Prediction is different than inference. It’s different from explanation.” Which is to say that the while the model can predict which counties are most likely to have similar graves in them in the future, it can’t explain why that is, and it isn’t particularly concerned with which variables make that difference.
But the teams at Data Cívica and the University of Ibero are.
“The problem with this type of violence is that it’s a very contextual violence,” Mónica Meltis, the Coordinator of Projects at Data Cívica explained in a phone interview. What she means is that it’s impossible to separate the counties that have hidden graves from the socioeconomic forces that define them.
Counties with hidden graves are likely to have a lower average income than other counties. They tend to be more rural than urban, and thus have smaller populations. They have higher numbers of indigenous residents than counties without hidden graves, as evidenced by lower county-wide scores on Spanish language tests in primary schools. Many of the counties have been found to have strong connections to drugs (in the form of opium or methamphetamine labs) and high homicide rates.
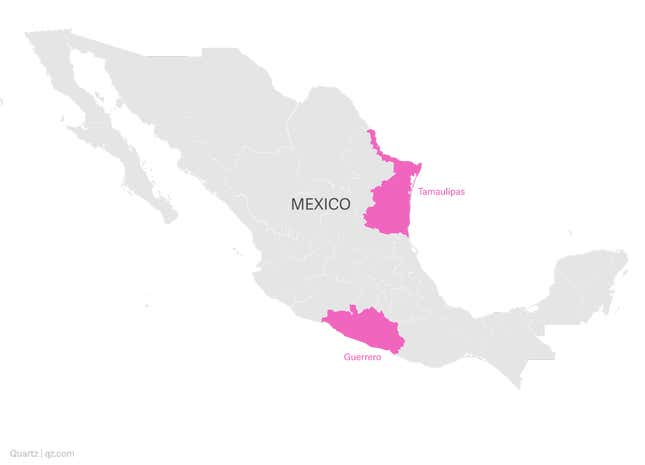
Their geographies are also significant: the counties with found graves tend to have highways, and thus be easily accessible by road. But they also evidence a pattern of being close to borders like the United States, Mexico’s northern neighbor, or Guatemala, the southern neighbor. The sea also counts as a border: the team at Data Cívica reports that three out of every ten disappearances happen in the states of Tamaulipas or Guerrero, both of which are coastal.
All of these characteristics make sense, in the matter-of-fact way that the best discoveries always do after the fact. But Meltis, Ball, and Denise González Núñez, the coordinator of University of Ibero’s Human Rights Program, all warn against drawing any hard conclusions. For one, the data that they’ve run the model on isn’t complete. Though the team has been able to use data from 2013 to predict accurate results for 2014, they haven’t yet been able to do the same for 2017. Before this can be done, Núñez’s team has to update their database with media mentions from 2016, a task that is forthcoming and time-consuming.
The project is also limited in the respect that it doesn’t answer any of the thorny questions around who is committing the crimes. The team can neither determine who is responsible for killing the victims nor guess as to the identities of the people within the mass graves. Their work provides only a compass of sorts, the barest map for those who must then do the difficult work of excavating those buried.

And of course, there’s the final fact that Ball in particular is careful to point out: “What we’re predicting is the probability of observation of a grave. We can only predict the counties that are likely to have graves that are like the ones we’ve observed in the past.”
His point is one that’s characteristic of all machine learning models. Models are deeply dependent on the data available. In the case of Mexico’s hidden graves, it’s highly possible that there are mass graves that have been so well hidden that no one has found them. These phantom graves, the unobserved unknowns, haven’t made their way into any datasets. And because they’re not in the data, it’s impossible to train a model on them. The work the group is doing cannot point to every hidden grave in the country. Rather, it can only help locate graves that are similar to those that have been found before.
Even so, the project represents a powerful beginning. For Núñez’s team, it’s part of a multi-year effort that will result in the May 2017 release of a comprehensive report about hidden graves in Mexico. Ultimately, the work is about more than reports, data, and models. As Metis puts it, “I don’t think that this is a project that we want to be sitting in our desks writing about. We want to go outside and find the people.”
Núñez says it even more simply: “This project is the means to obtain something else…to guarantee the human right to truth.”