
Lawyers today need to understand the relevant types of components to assist their machine learning (ML) clients in their legal matters.
Understanding the basics of ML is important for attorneys who have clients, for example, who need legal advice on protecting ML innovations and understanding what should be protected, preparing a licensing agreement and need to know what is being licensed, or in preparing a joint venture agreement and need to know what is being contributed.
Learning what the basic components that are being contributed and potentially monetized will help attorneys advising on ML transactions better define what their clients are doing and how to draft legal instruments to protect them.
ML technology is a form of artificial intelligence that involves computer algorithms that improve over time. The technology has a defined format for input, a defined format for output, and a specific algorithm (or logic), where the connection between each input/output combination is generally unknown. Because of the way it is built, it can at a high level, ML can be thought of as a black box, where in response to an input data query, the black box will provide a desired output.
From an attorney’s perspective, since the logic may prove ultimately unknown or unknowable from a practical point of view, legal relationships are often defined based on the building of the black box. For example, defining the rights, compensations, and responsibilities of various parties involved in the production of the black box.
What Goes Into a Black Box
From a technological standpoint, ML is a black box because, unlike a traditional heuristic (i.e., human programmed) software code, the logic applied by the ML black box is generally unknown (and as a practical matter unknowable).
Instead, what computer engineers know is how the ML black box is built, including:
- The specified form of input data query (i.e., a defined format for input);
- The ML algorithm or model (i.e., a specific algorithm or logic);
- The training set of data samples (including inputs in a defined format and corresponding outputs in a defined format), including the features, their labels and tags; and
- The specified form of output based on the tags (i.e., a defined format for output).
As shown in the graphic below, these four components are how the black box is built and can be used to define a particular ML system, even if the actual logic implemented is never known.
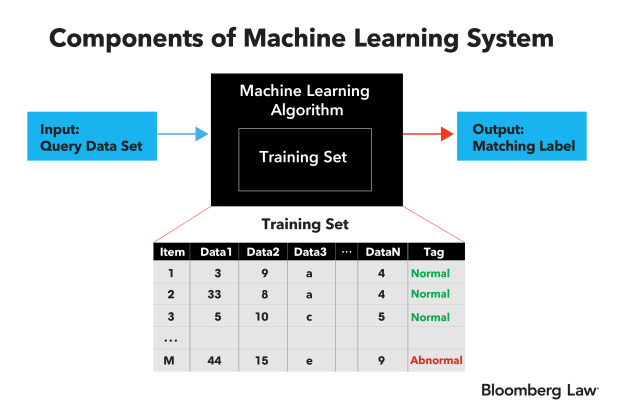
FIG. 1: Components of Machine Learning System
The training set of data or images is composed of a large number of samples that include common features (or data, as reflected as Data 1, Data 2, etc. in the graphic) and tags that usually reflect a qualitative judgment as to the meaning of the sample data set.
Consider a training set involving medical data. Each sample may reflect a set of test results (e.g., blood tests) taken of a specific patient at a specific time, including the doctor’s tag as to the meaning of the blood test (e.g., normal, abnormal or perhaps a diagnosis like diabetes, heart disease, etc.).
In this example, each column of features includes a label (e.g., an identifier of the type of test taken) in addition to the specific data items for each sample taken. Each row in the table is a separate sample. To be useful in training the ML algorithm, a training set will need to include a large number of samples, ideally thousands, or perhaps tens/hundreds of thousands or more of samples. Further, each sample included in the training set which lacks a useful tag is useless, and, in general, comprised mostly of just noise.
Training sets may also utilize images, videos, and/or sounds instead of, or in combination with, alpha-numeric data. In the simplest case, each image, video, or sound file will be a sample and will include at least one tag.
As an example, in the context of the previous medical example, the image may be an x-ray, and the tag may be the diagnosis of malignant or benign. As another example, a video could be a movie with a tag that is a rating, (e.g., G, PG, R, M, etc.). A sound could be an audio file, or a portion of an audio file, with a label such as “window opening” or “car honking.”
Training sets can also be more complex by including a combination of alpha-numeric data and images, videos, and/or sounds, for each sample. For present purposes, the key concept is that a training set includes many samples and each sample includesfeatures with labels”and one or more tags.
Understand and Define Input and Output
When defining a ML system, it is important to understand both the defined form of query that will be the input of the black box to be tested against the training set, and the defined form of the output to come out the black box.
Typically, the query will include one or more features defined in the training set (e.g., the blood tests run against the medical data training set discussed above). If the features of the query do not match the features in the training set, the query should be normalized to produce a useful output.
The output in turn will typically match the tags of the training set. Again, turning to the medical data example discussed previously, if the blood tests are labeled normal or abnormal, then the output of the ML system will typically also be normal or abnormal.
To allow the query to be tested against the training set to generate an output, some form of ML algorithm or model would need to be trained by the training set (e.g., providing the inputs and corresponding outputs from the training set to the ML algorithm). Examples of models include neural networks, deep neural networks, and convolutional neural networks, to name a few.
When a training set, is applied against the ML algorithm or model, the computer(s) running the ML algorithm or model will automatically generate logic (which is generally considered an unknown) to test the query.
Essential Understandings
Thus, when defining the legal relationship of the parties in terms of their respective rights, compensation and responsibilities, it essential to understand and consider:
- The training set;
- The ML algorithm or model;
- The form of the input query; and
- The form of the output result.
The relative contribution of each party to these basic components can then be defined and measured in whatever legal analysis or services are being provided, whether it be as part of a licensing transaction, seeking copyright and/or patent protection, or even assessing liability in tort law when something goes wrong.
This column does not necessarily reflect the opinion of The Bureau of National Affairs, Inc. or its owners.
Author Information
Charles R. Macedo is a partner at Amster, Rothstein & Ebenstein LLP where his practice focuses on all facets of intellectual property law, including patent, copyright, licensing computer implemented inventions such as machine learning and artificial intelligence innovation.
He would like to thank Dr. Brian Amos, Michael Jones, Chandler Sturm, and Herbert Blassengale for their assistance in preparing this article.
Learn more about Bloomberg Tax or Log In to keep reading:
Learn About Bloomberg Tax
From research to software to news, find what you need to stay ahead.
Already a subscriber?
Log in to keep reading or access research tools.