

At DoorDash, real time events are an important data source to gain insight into our business but building a system capable of handling billions of real time events is challenging. Events are generated from our services and user devices and need to be processed and transported to different destinations to help us make data-driven decisions on the platform. To name a few use cases:
- Almost all events need to be transported to our OLAP data warehouse for business analysis. For example, the Dasher assignment team (Dasher is our name for delivery drivers) relies on assignment data in the data warehouse to detect any bugs in their assignment algorithm.
- Some events will be further processed by downstream systems. For example, delivery events are processed by our ML platform to generate real time features like recent average wait times for restaurants.
- Some mobile events will be integrated with our time series metric backend for monitoring and alerting so that teams can quickly identify issues in the latest mobile application releases. For example, any checkout page load errors from our DoorDash consumer application need to be sent to Chronosphere for monitoring.
How our legacy system worked
Historically, DoorDash has had a few data pipelines that get data from our legacy monolithic web application and ingest the data into Snowflake, our main data warehouse. Each pipeline is built differently, can only process one kind of event, and involves multiple hops before the data finally gets into the data warehouse. An example is shown as Figure 1:

There are several problems with this approach:
- It is cost inefficient to build multiple pipelines that are trying to achieve similar purposes.
- Mixing different kinds of data transport and going through multiple messaging/queueing systems without carefully designed observability around it leads to difficulties in operations.
These resulted in high data latency, significant cost, and operational overhead.
Subscribe for weekly updates
Introducing Iguazu our event processing system
Two years ago, we started the journey of creating a real time event processing system named Iguazu to replace the legacy data pipelines and address the following event processing needs we anticipated as the data volume grows with the business:
- Heterogeneous data sources and destinations: Data ingest from a variety of data sources including the legacy monolithic web application, microservices and mobile/web devices, and delivery to different destinations including third-party data services. Reliable and low latency data ingest into the data warehouse is a high priority.
- Easily accessible: A platform that makes it easy for different teams and services to tap into the streams of the data and build their own data processing logic.
- End-to-end schema enforcement and schema evolution: Schema only improves data quality, but also facilitates easy integration with data warehouses and SQL processing.
- Scalable, fault-tolerant, and easy to operate for a small team: We want to build a system that can easily scale to the business need with minimal operational overhead.
To meet those objectives, we decided to shift the strategy from heavily relying on AWS and third-party data services to leveraging open source frameworks that can be customized and better integrated with DoorDash’s infrastructure. Stream processing platforms like Apache Kafka and Apache Flink have matured in the past few years and become easy to adopt. These are excellent building blocks we can leverage to build something ourselves.
In the past two years, we built the real time events processing system and scaled it to process hundreds of billions of events per day with a 99.99% delivery rate. The overall architecture of the system is depicted in Figure 2 below. In the following sections, we are going to discuss in detail the design of the system and how we solved some major technical challenges:
- Simplifying event publishing with unified API and event format to avoid bottlenecks in adoptions
- Providing multiple abstractions for consuming the events for different kinds of data consumers
- Automating the onboarding process using Github automations and workflows in an Infrastructure As Code environment
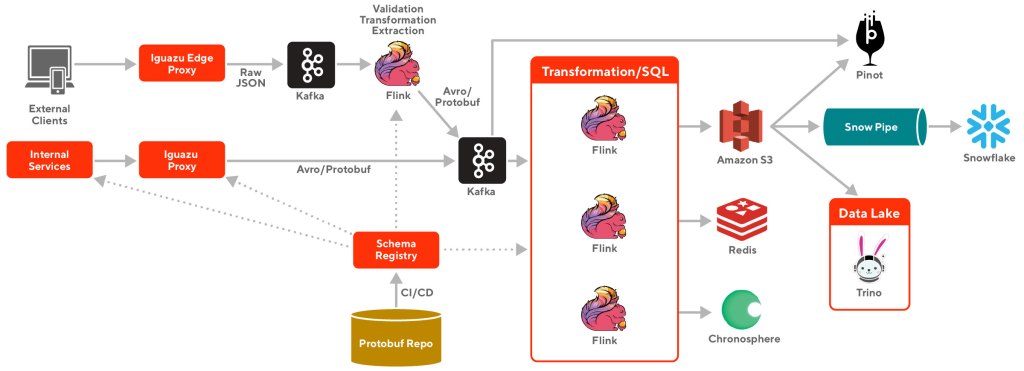
Simplify and optimize event producing
The first step to building a processing system was choosing the best technology and approach to processing the events. We choose Apache Kafka as our pub/sub system for streaming data because Kafka has proved to be an excellent solution to unify heterogeneous data sources while providing high throughput and high performance.
Leveraging and enhancing Kafka Rest Proxy
We want every DoorDash service to be able to easily produce events to Kafka. An obvious choice is to create a Kafka client and integrate it with all services. However, this approach has a few disadvantages:
- It will be a burden for every service to configure Kafka connections, which is likely to have issues for teams that are not familiar with Kafka and slow down the adoption
- It will be difficult to have uniform and optimized Kafka producer configuration across different services
- A direct connection to Kafka is infeasible for mobile and web applications
Therefore, we decided to leverage Confluent’s open source Kafka Rest Proxy for event producing. The proxy provides us a central place where we can enhance and optimize event producing functionalities without having to coordinate with client applications. It provides abstractions over Kafka with HTTP interface, eliminating the need to configure Kafka connections and making event publishing much easier. The record batching, which is critical to reduce broker’s CPU utilization, is also significantly improved due to the capability of batching across different client instances and applications.
The Kafka rest proxy provides all the basic features we need out of the box, including:
- Supporting different kinds of payload formats, including JSON and binaries
- Supporting batch, which is crucial to reduce processing overhead for both client applications and Kafka brokers
- Integration with Confluent’s schema registry makes it possible to validate and convert the JSON payload with schema
On top of that, we customized the rest proxy to our needs and added the following features:
- The capability to produce multiple Kafka clusters. The ability to produce multiple clusters is critical to us as our events quickly expanded to multiple Kafka clusters and the event-to-cluster mapping is an important abstraction we have in our system.
- Asynchronous Kafka producing requests. Having asynchronous production eliminates the need to first get brokers’ acknowledgment before responding to the client’s requests. Instead, the response is sent back immediately after the payload is validated and added to the Kafka producer’s buffer. This feature greatly reduces the response time, and improves the batching and system’s overall availability. While this option may lead to minor data losses when Kafka is unavailable, the risk is offset by proxy side producer retries and close monitoring of acknowledgments received from brokers.
- Pre-fetching Kafka topic metadata and producing test Kafka records as part of the Kubernetes pod readiness probe. This enhancement will ensure that the proxy pod will warm up all the caches and Kafka connections to avoid cold start problems.
- Supporting Kafka header as part of the proxy produce request payload. Our event payload format relies on the event envelope which is part of the Kafka header in the produce record. We will cover more on our event payload format and serialization in later sections.
Optimizing producer configuration
While Kafka’s default configurations work well for systems requiring high consistency, it is not most efficient for non-transactional event publishing and processing where throughput and availability are important. Therefore, we fine-tuned our Kafka topic and proxy producer’s configurations to achieve high efficiency and throughput:
- We use a replication factor of two with one minimal in-sync replica. Compared to the typical configuration of three replicas, this saves the disk space and reduces the broker’s CPU utilization on replication, while still providing adequate data redundancy.
- The producer is configured to receive acknowledgment from the broker as soon as the leader of the partition, not the followers, has persisted the data. This configuration reduces the response time of the produce request.
- We leverage Kafka's sticky partitioner by setting a reasonable linger time between 50ms to 100ms, which significantly improves batching and reduces broker’s CPU utilization.
Altogether, this tuning has reduced the Kafka broker CPU utilization by 30 to 40%.
Running Rest Proxy in Kubernetes
The Kafka rest proxy turns out to be easy to build and deploy in our own Kubernetes infrastructure. It is built and deployed as an internal service and leverages all the CI/CD processes offered by DoorDash’s infrastructure. Kubernetes horizontal pod autoscaling is enabled on the service based on CPU utilization. This significantly reduces our operational overhead and saves cost.

Now that we described simplified and efficient event producing, let’s focus on what we have done to facilitate event consuming in the next section.
Event processing with different abstractions
As mentioned in the beginning, one important objective for Iguazu is to create a platform for easy data processing. Flink’s layered API architecture fits perfectly with this objective. Data Stream API and Flink SQL are the two main abstractions we support.
We chose Apache Flink also because of its low latency processing, native support of processing based on event time, fault tolerance, and out-of-the-box integration with a wide range of sources and sinks, including Kafka, Reddis (through a third-party OSS), ElasticSearch, and S3.
Deployment with Helm in Kubernetes
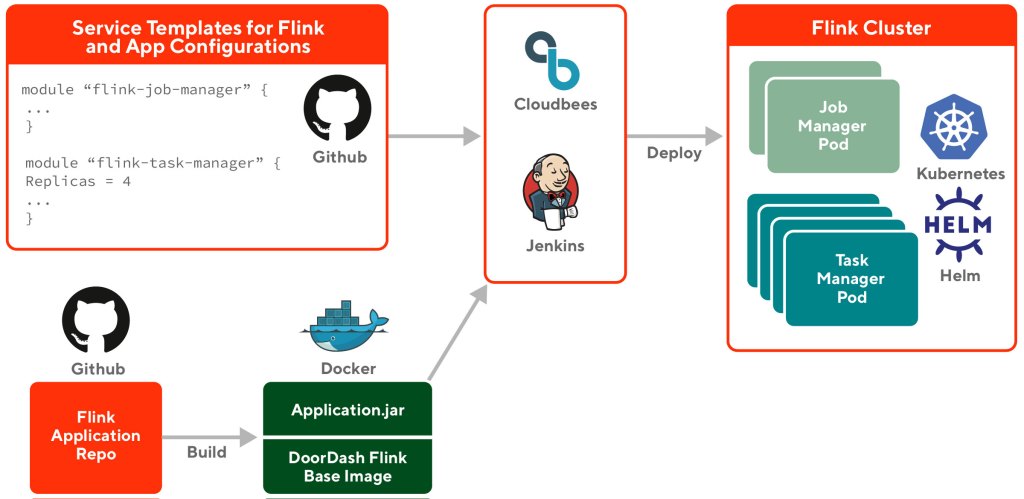
Our platform provides a base Flink docker image with all the necessary configurations that are well integrated with the rest of DoorDash Kubernetes infrastructure. Flink’s high availability setup and Flink metrics are available out of the box. For better failure isolation and the ability to scale independently, each Flink job is deployed in standalone mode, as a separate Kubernetes service.
When developing the Flink application using data stream APIs, engineers will start by cloning a Flink application template and then add their own code. The application and Flink job’s configuration - like parallelism and task manager count - will be defined in a terraform template. In the build process, a docker image will be created with the combined application jar file and our internal Flink base docker image. The deployment process will take both the terraform template and the application docker image and deploy the application in a standalone Flink job cluster in our K8s cluster from a generated Helm Chart. The process is illustrated in the following diagram:
Providing SQL Abstraction
While Flink’s data stream API is not difficult to understand for backend engineers, it still presents a major hurdle to data analysts and other casual data users. For those users, we provide a platform to create Flink applications declaratively using SQL without having to worry about infrastructure-level details. The details of the work are available in this blog.
When developing a SQL based application, all the necessary processing logic and wiring are captured in a YAML file which is simple enough for everyone to read or author. The YAML file captures a lot of high-level abstractions, for example, connecting to Kafka source and output to different sinks. Here is an example of such YAML file:
sources:
- name: canary_store_order_count
type: REALTIME
compute_spec:
type: RIVIERA
riviera_spec:
kafka_sources:
- cluster: default
topic: store_timeline_events
proto_class: "com.doordash.timeline_events.StoreTimelineEvent"
sql: >-
SELECT
store_id as st,
SUM(CAST(has_store_order_confirmed_data AS INT)) as
saf_st_p20mi_order_count_sum_canary
FROM store_timeline_events
GROUP BY HOP(_time, INTERVAL '20' SECONDS,
INTERVAL '20' MINUTES),
store_id
resource_config:
number_task_manager: 2
memory: "1Gi"
cpu: "2400m"
features:
- name: canary_store_order_count
source: canary_store_order_count
materialize_spec:
sink:
- prod_canary_features
feature_ttl: 1200
metadata_spec:
description: Store Order Sum over 20 minute
To create the Flink job, the user only needs to create a PR with the YAML file. Upon the merge of the PR, a CD pipeline will be kicked off and compile the YAML file into a Flink application and deploy it.
In the above two sections, we covered events producing and consuming in Iguazu. However, without a unified event format, it’s still difficult for producers and consumers to understand each other. In the next section, we will discuss the event format which serves as a protocol between producers and consumers.
Event format, serialization, and schema validation
From the very beginning, we defined a unified format for events produced and processed in Iguazu. The unified event format greatly reduced the barrier in consuming events and reduced the frictions between event producers and consumers.
All events have a standard envelope and payload. The envelope contains context of the event (creation time and source, for example), metadata (including encoding method) and references to schema. The payload contains the actual content of the event. The envelope also includes non-schematized event properties as a JSON blob. This JSON section in the envelope helps to make parts of the event schema flexible where the changes do not involve a formal schema evolution process.
Event payload produced from internal microservices will be schema validated and encoded. Invalid payloads will be dropped directly at the producer side. For events produced from mobile/web devices, they are in raw JSON format and we use a separate stream processing application to do schema validation and transformation to the schematized format for downstream processes to consume.
We created serialization/deserialization libraries for both event producers and consumers to interact with this standard event format. In Kafka, the event envelope is stored as a Kafka record header and the payload is stored as the record value. For event consumers, our library will decode the Kafka header and value and recreate the event for the consumer to process.
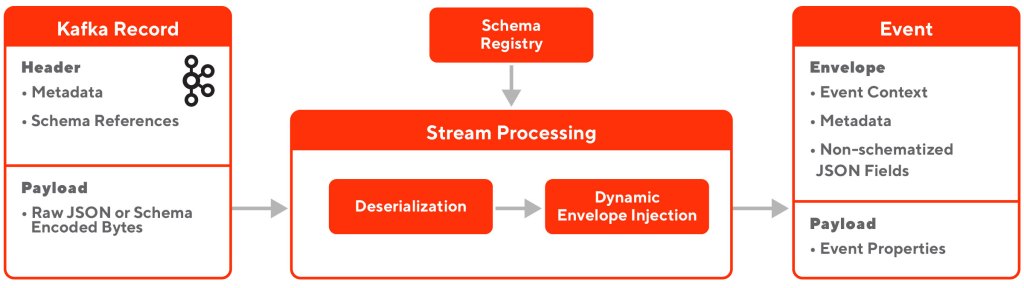
Almost all of our microservices are based on GRPC and Protobuf. All events are defined by Protobuf in a centrally shared Protobuf Git repository. At the API level, our definition of an Event is a wrapper around a Protobuf message to make it easy for our microservices to use. However, for most of the final destinations of the event, the Avro format is still better supported than Protobuf. For those use cases, our serialization library takes the responsibility of seamlessly converting the Protobuf message to Avro format, thanks to Avro’s protobuf library, and converting back to the Protobuf message when needed.
We heavily leveraged Confluent’s schema registry for generic data processing. All events are registered with the schema registry. With the recent Protobuf schema support introduced in the Confluent schema registry, we achieved the ability of generic data processing with both Protobuf and Avro schema.
One challenge we faced in the beginning is how we can enforce and automate the schema registration. We do not want to register the schema at the runtime when the events are produced because:
- It would dramatically increase the schema update requests at a certain time, causing scalability issues for the schema registry.
- Any incompatible schema change would cause schema update failures and runtime errors from the client application.
Instead, it would be ideal to register and update the schema at build time to reduce the update API call volume and have a chance to catch incompatible schema changes early in the cycle.
The solution we created is to integrate the schema registry update as part of the CI/CD process for our centralized Protobuf Git repository. When a Protobuf definition is updated in the pull request, the CI process will validate the change with the schema registry. If it is an incompatible change, the CI process would fail. After the CI passes and the pull request is merged, the CD process will actually register/update the schema with the schema registry. The CI/CD automation not only eliminates the overhead of manual schema registration, but also guarantees:
- Detection of incompatible schema changes at build time, and
- The consistency between released Protobuf class binaries and the schemas in the schema registry.
In the above sections, we discussed event producing, consuming, and their binding through the unified event format in Iguazu. In the next section, we will describe Iguazu’s integration with its most important data destination - the data warehouse - in a low latency and fault-tolerant fashion.
Data Warehouse Integration
As mentioned at the beginning of the article, data warehouse integration is one of the key goals of Iguazu. Snowflake is still our main data warehouse solution. We expect events to be delivered to Snowflake with strong consistency and low latency.
The data warehouse integration is implemented as a two-step process.
In the first stage, data is consumed by a Flink application from Kafka and uploaded to S3 in the Parquet file format. This step helps to decouple the ingest process from Snowflake itself so any Snowflake related failures will not impact the stream processing and the data can be backfilled from S3, given Kafka’s limited retention. In addition, having the Parquet files on S3 enables data lake solutions, which we explored later with our in-house Trino installation.
The implementation of uploading data to S3 is done through Flink’s StreamingFileSink. When completing an upload for a Parquet file as part of Flink’s checkpoint, StreamingFileSink guarantees strong consistency and exactly-once delivery. StreamingFileSink also allows customized bucketing on S3, which we leveraged to partition the data at the S3 directory level. This optimization greatly reduced the data loading time for downstream batch processors.
At the second stage, data is copied from S3 to Snowflake via Snowpipe. Triggered by SQS messages, Snowpipe enables loading data from S3 files as soon as they’re available. Snowpipe also allows simple data transformation during the copying process. Given its declarative nature, it is a great alternative compared to doing that in stream processing.
One important note is that each event has its own stream processing application for S3 upload and its own Snowpipe. As a result, we can scale pipelines for each event individually and isolate failures.
So far we covered how data flows from end to end from clients to the data warehouse. In the next section, we will discuss the operational aspect of Iguazu and see how we are making it self-serve to reduce the operational burdens.
Working towards a self-serve platform
As mentioned above, to achieve failure isolation, each event in Iguazu has its own pipeline from Flink job to Snowpipe. However, this requires more infrastructure setup and makes the operation a challenge.
At the beginning, onboarding a new event into Iguazu is a support-heavy task. DoorDash heavily relies on the Infrastructure-As-Code principle and most of the resource creation, from Kafka topic to service configurations, involves pull requests to different terraform repositories. This makes automation and creating a high level abstraction a challenging task. See the diagram below for the steps involved in onboarding a new event.

To solve this issue, we worked with our infrastructure team to set up the right pull-approval process and automate the pull requests using Git automation. Essentially a Github App is created where we can programmatically create and merge pull requests from one of our services which acts as a controller. We also leveraged the Cadence workflow engine and implemented the process as a reliable workflow. This whole automation reduced the event onboarding time from days to minutes.
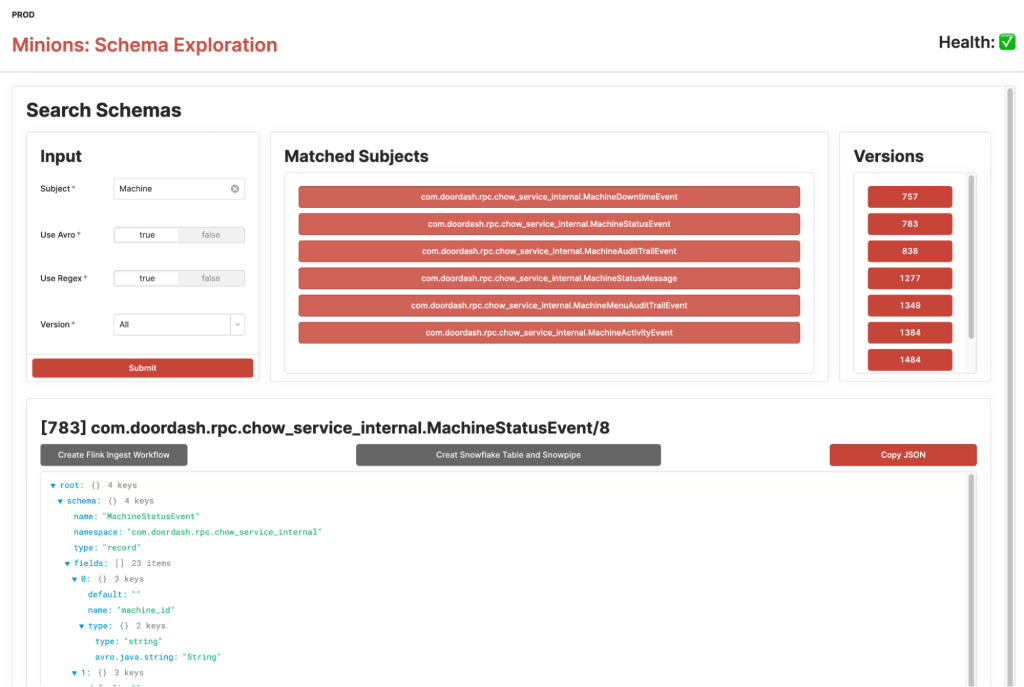
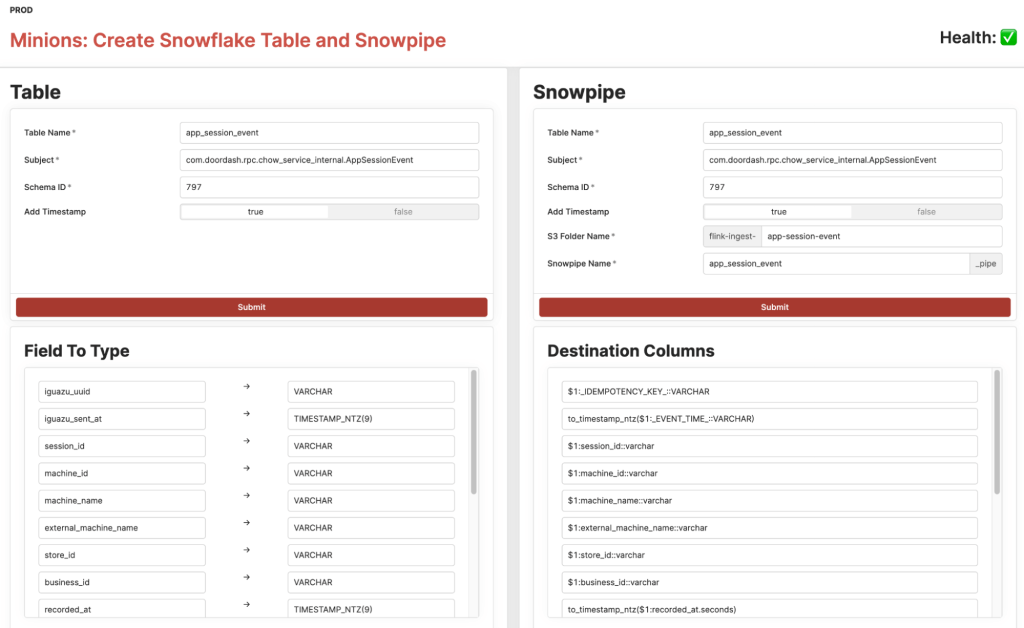
To make it one step closer to being self-servable, we created UIs using the Retool framework for users to explore schema and onboard an event from there. Users can search for a schema using regex, pick the right schema for the event, start the workflow to create necessary resources and services, and have the opportunity to customize the Snowflake table and Snowpipe.
Our ultimate goal of Iguazu is to make it a self-serve platform, where users can onboard an event by themselves with the right abstraction and minimal support or human intervention.
Learnings and Future Work
We found it important to create the event processing system with a platform mindset. Ad-hoc solutions where different technologies are piled on each other is not only inefficient but also difficult to scale and operate.
Picking the right framework and creating the right building blocks is crucial to ensure success. Apache Kafka, Apache Flink, Confluent Rest Proxy and Schema registry proves to be both scalable and reliable. Researching and leveraging the sweet spots of those frameworks dramatically reduced the time needed to develop and operate this large scale event processing system.
To make the system user friendly and easy to adopt requires the right abstractions. From the declarative SQL approach, seamless serialization of events, to the high level user onboarding UI, we strive to make it an easy process so that our users can focus on their own business logic, not our implementation details.
There is still a lot we want to achieve with Iguazu. We have already started a journey of building a Customer Data Platform on top of Iguazu where we can easily transform and analyze user data in a self-serve manner. Sessionization is an important use case we want to address. In order to be able to sessionize a huge amount of data, we started to enhance our support of Flink stateful processing by leveraging Kubernetes StatefulSet, persisted volumes and exploring new ways of deployment using Spinnaker. Better integration with data lake is another direction we are heading into. Together with SQL abstraction and the right table format, direct data lake access from stream processing applications enables backfill and replay using the same application and provides another alternative to Lambda architecture.
Stay tuned and join us on this adventure.
Acknowledgements
Applauses to team members who directly contributed to Iguazu over the past two years: Ahmed Abdul-Hamid, Chen Yang, Eleanore Jin, Ijesh Giri, Kunal Shah, Min Tu, Mohan Pandiyan, Nikhil Patil, Parul Bharadwaj, Satya Boora, Varun Narayanan Chakravarthy.
Thanks also go to team members who closely collaborated with us: Adam Rogal, Akshat Nair, Attila Haluska, Carlos Herrera, Dima Goliy, Gergely Nemeth, Hien Luu, James Bell, Jason Lai, Karthik Katooru, Kenny Kaye, Matan Amir, Nick Fahrenkrog, Roger Zeng, Sudhir Tonse, Wuang Qin.












Good work. Love to see you guys using schema registry. Schema versions are so important when you need to make a breaking change but don’t want to do a ‘big bang’ update to all the apps that use it.
Thank for you writing this blog. Everyone on my team found it very useful and we been using it to inform certain components of our own streaming architecture.
how is iguazu proxy routing incoming events to different kafka topic ?
Topic name is part of URI in the Kafka Rest Proxy request.