Using Splunk’s Machine Learning Toolkit to Predict Films I’d Like to Watch
Setting the Scene
It feels as if I have watched some abundantly average films in recent times, and I do not seem to be the only one suffering from this admittedly, relatively insignificant problem. Nevertheless, this problem persisted and had me wondering how I could use what I’ve learned over the past 14 weeks as a Splunktern to turn a chapter in the quality of films I watch. A potential answer to my problem - machine learning.

For those of you who don’t know, Splunk is a super cool, vibrant technology company based in San Francisco that works with organisations to turn their data into doing. Over the course of my internship, I have been immersed into this Splunky culture and encouraged to follow my interests to learn about new topics which seemed distant to me at the time. Therefore, here is my attempt at using machine learning to create a watchlist of films I would be predicted to like so I never have to watch an average film again (hopefully).
The Method
To start things off, I needed the data. IMDB is a highly popular film ratings website where titles are rated 1-10 by the public and then given an average rating. I downloaded 5 datasets from the IMDB website and ingested them into Splunk to start the process of discovering insights about millions of titles. To do this I configured dozens of automatic and static lookups to bring together the relevant information from each of the 5 datasets which allowed me to filter out unwanted events and start my analysis. At this point, these were the relevant fields I had per film: primaryTitle, averageRating, numVotes, startYear, runtimeMinutes, genres, Name (director), primaryName (main cast) and more.

From here I entered a search for approximately 80 specific films within my Splunk instance. Half of which I consider to be my favourite films and the rest are ones I dislike. For these 80 or so films, I created new field-value combinations using the eval command and the if function where my favourite films had combinations of ‘Like: True’ and ones I disliked being assigned ‘Like: False’. What I did here was specify my film preferences so the later predictions are tailored to me.
Splunk’s Machine Learning Toolkit
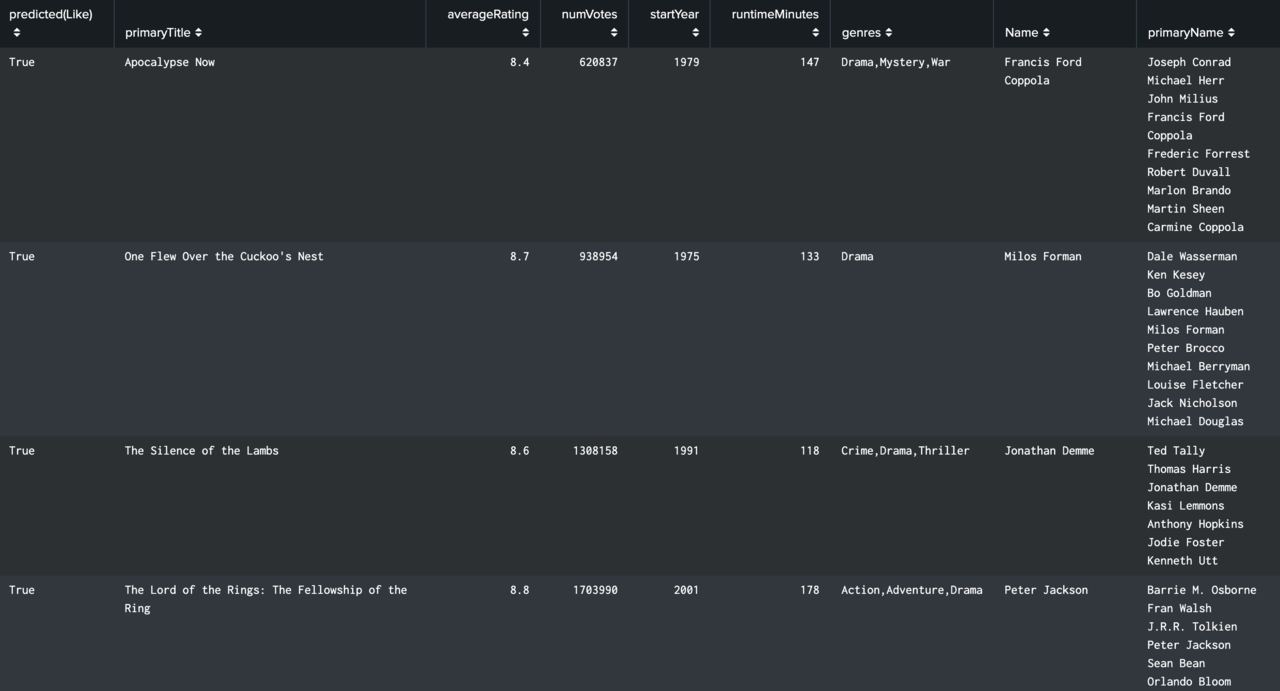
This is where I started using the Machine Learning Toolkit (MLTK) - a free app on Splunk Base which empowers those seeking a DIY approach to making custom machine learning models. To create a model in the MLTK you need to input training data for the model to understand what it is working from. In this case, it was the list of approximately 80 films with values for the ‘Like’ field. The following fields were used so trends within the ‘Like: True’ and ‘Like: False’ films could be established and later searched for: averageRating, numVotes, startYear, runtimeMinutes, genres, Name, and primaryName. Using the fit and apply commands, I employed the RandomForestClassifier algorithm to use this training data to classify the predicted value of a new field, ‘predicted(Like)’, for all films in my instance, most of which I haven’t seen. I now have a list of 300 or so films which I am predicted to like – ‘predicted(Like): True’ – and will slowly make my way through watching. I also have a list of several thousand films I am predicted not to like - ‘predicted(Like): False’ which I will do my best to avoid.
This list summarises how I applied machine learning to my data:
- Tell Splunk which films I do and do not like.
- Splunk works out the trends among the numeric and categorical fields of the ‘Like: True’ and ‘Like: False’ films.
- Splunk uses these trends and searches for films with characteristics which either more closely match the trends of ‘Like: True’ or ‘Like: False’ films.
- Splunk then classifies the value of a predicted field – ‘predicted(Like)’ – for thousands of films.
- ‘predicted(Like): True’ films are ones which I am predicted to like watching based on my specified preferences. Some examples include: Million Dollar Baby, Casino and Groundhog Day.
Testing the Predictions
As you can imagine, going through films which I have already watched and checking whether they have the correct ‘predicted(Like)’ values is not exactly automated and lacks accountability so my next step was to quantify the accuracy of my predictions with metrics.
One test I did was this. I worked out what percentage of my favourite films belong to certain genres and tested to see whether my predictions would represent my preferences whilst also comparing these against the genre makeup for all films in my instance (films tend to have multiple genres assigned to them).

From this, I found that 73.17% of my favourite films – ‘Like: True’ – have the genre of drama assigned to it, whilst 21.95% are assigned action. This is compared to 49.86% and 29.81% respectively for the total number of films in my instance. In the list of films I have been predicted to like, I was glad to see that my preferences for genre makeup were accurately recognised and reciprocated back to me – 77.33% for drama and 18.33% for action. This is especially telling when comparing this to the genre makeup of the total number of films in my instance which demonstrate what ballpark of percentages I would likely receive if the films were predicted completely randomly.
Final Thoughts
Whilst my model for predicting films seems to have passed initial tests, it is important to note that when dealing with machine learning there is always room for improvement in how well you refine your processes. Whether this is in the data crunching phase, the searches you use when creating the model, or the methods by which you test it. This is because in the field of data science/analytics you can arrive at the correct solution in a multitude of different ways therefore, adhering to best practices and continuous improvements will always be worthwhile.
From this, I hope to have now solved my significant relatively insignificant problem and look forward to never watching an average film ever again.
*Information courtesy of: IMDB: (http://www.imdb.com): Used with permission.
Global Director Security, Fraud, Compliance @ Splunk
2yJames Hodge
Regional Account Manager - Public Sector
2yBetter double check the data, not liking Die Hard seems like an outlier Brett W.
Sales Engineer at CrowdStrike (LogScale)
2yCool!