También podría gustarte
- Analisis FodaDocumento24 páginasAnalisis FodaJaime Pelaez99% (83)
- D-33 Lineas de Investigacion 2023 5Documento80 páginasD-33 Lineas de Investigacion 2023 5Limbania Bernal100% (1)
- Antropologia AudiovisualDocumento16 páginasAntropologia AudiovisualCarola Zenteno SaavedraAún no hay calificaciones
- Estética del reconocimiento: Fragmentos de una crítica social de las artesDe EverandEstética del reconocimiento: Fragmentos de una crítica social de las artesAún no hay calificaciones
- Arqueología transmedia en América Latina: mestizajes, identidades y convergenciasDe EverandArqueología transmedia en América Latina: mestizajes, identidades y convergenciasAún no hay calificaciones
- Indicios visionarios para una prehistoria de la alucinaciónDe EverandIndicios visionarios para una prehistoria de la alucinaciónAún no hay calificaciones
- Una Serie introductoria: Un enfoque sociocultural del comportamientoDe EverandUna Serie introductoria: Un enfoque sociocultural del comportamientoAún no hay calificaciones
- Zoveck - Manual Ilustrado de Magia BlancaDocumento18 páginasZoveck - Manual Ilustrado de Magia BlancaVladimir Atahualpa100% (1)
- Mujeres y saberes digitales: Las otras alfabetizaciones necesariasDe EverandMujeres y saberes digitales: Las otras alfabetizaciones necesariasAún no hay calificaciones
- Braidotti Rosi Devenir Mujer MetamorfosisDocumento33 páginasBraidotti Rosi Devenir Mujer MetamorfosisTesalianowAún no hay calificaciones
- 6 La Producción Social de ComunicaciónDocumento31 páginas6 La Producción Social de ComunicaciónAleXander SanguchoAún no hay calificaciones
- Cuerpos inciertos: Potencias, discursos y dislocaciones en las corporalidades contemporáneasDe EverandCuerpos inciertos: Potencias, discursos y dislocaciones en las corporalidades contemporáneasAún no hay calificaciones
- De las políticas educativas a las prácticas escolaresDe EverandDe las políticas educativas a las prácticas escolaresCalificación: 5 de 5 estrellas5/5 (1)
- Inteligencia artificial: Conversaciones ChatGPTDe EverandInteligencia artificial: Conversaciones ChatGPTAún no hay calificaciones
- Cultura_RAM: Mutaciones de la cultura en la era de su distribución electrónicaDe EverandCultura_RAM: Mutaciones de la cultura en la era de su distribución electrónicaAún no hay calificaciones
- Sujetos y subjetividades: Aproximaciones empíricas en tiempos actualesDe EverandSujetos y subjetividades: Aproximaciones empíricas en tiempos actualesAún no hay calificaciones
- Baudrillard Cultura y SimulacroDocumento13 páginasBaudrillard Cultura y SimulacroyaglopezAún no hay calificaciones
- MÁQUINAS PARA VER Y OÍR AL LÍMITE DEL TIEMPO: Hacia una crítica práctica de la comunicaciónDe EverandMÁQUINAS PARA VER Y OÍR AL LÍMITE DEL TIEMPO: Hacia una crítica práctica de la comunicaciónAún no hay calificaciones
- Escrituras descentradas: El ensayo de los escritores en América latina (1970-2010)De EverandEscrituras descentradas: El ensayo de los escritores en América latina (1970-2010)Aún no hay calificaciones
- Bolvin, Rosato, Arribas - Constructores de OtredadDocumento66 páginasBolvin, Rosato, Arribas - Constructores de OtredadYamila Baigorria100% (1)
- Escenas de proyección: Reenvíos del sujeto iluministaDe EverandEscenas de proyección: Reenvíos del sujeto iluministaAún no hay calificaciones
- Goffman, Erving - Los Momentos y Sus HombresDocumento115 páginasGoffman, Erving - Los Momentos y Sus Hombreswaldemarclaus100% (18)
- Cuerpo General de Bomberos Voluntarios Del PerúDocumento5 páginasCuerpo General de Bomberos Voluntarios Del PerúJhony AvilaAún no hay calificaciones
- Ihde, Don - Los Cuerpos en La Tecnologia UocDocumento142 páginasIhde, Don - Los Cuerpos en La Tecnologia UocJan Canteras Zubieta100% (2)
- Tecnociencia y CiberculturaDocumento342 páginasTecnociencia y CiberculturaAle1963100% (4)
- Salir de la violenciaDocumento18 páginasSalir de la violenciapintodanielaAún no hay calificaciones
- Luchas minoritarias y líneas de fuga en América LatinaDe EverandLuchas minoritarias y líneas de fuga en América LatinaAún no hay calificaciones
- 15 - Cuerpos Políticos y Agencia - Desbloqueado PDFDocumento220 páginas15 - Cuerpos Políticos y Agencia - Desbloqueado PDFJuan PabloCbaAún no hay calificaciones
- La Gran Conversión Digital Milad Doueihi PDFDocumento114 páginasLa Gran Conversión Digital Milad Doueihi PDFJazmín Bonilla67% (3)
- Una coartada metodológica: Abordajes cualitativos en la investigación en comunicación, medios y audienciasDe EverandUna coartada metodológica: Abordajes cualitativos en la investigación en comunicación, medios y audienciasAún no hay calificaciones
- Estilos de vida y gustos de clase según Pierre BourdieuDocumento11 páginasEstilos de vida y gustos de clase según Pierre BourdieuMa Magdalena DAún no hay calificaciones
- Bourdieu Pierre Que Significa HablarDocumento80 páginasBourdieu Pierre Que Significa Hablarfifanorris100% (9)
- Mujeres e imaginarios de la globalización: Reflexiones para una agenda teórica global del feminismoDe EverandMujeres e imaginarios de la globalización: Reflexiones para una agenda teórica global del feminismoAún no hay calificaciones
- DEBATE CEU Rectoría LIBRO JULIETA PDFDocumento517 páginasDEBATE CEU Rectoría LIBRO JULIETA PDFyumeliAún no hay calificaciones
- Michel Foucault TopologíasDocumento13 páginasMichel Foucault TopologíascarmendegarzaAún no hay calificaciones
- Paponi: Resignificaciones de La SubjetividadDocumento26 páginasPaponi: Resignificaciones de La SubjetividadmanriquemarianelaAún no hay calificaciones
- Ontología CyborgDocumento7 páginasOntología CyborgLiz KornerAún no hay calificaciones
- Monstruos cotidianosDocumento16 páginasMonstruos cotidianosBere BeresAún no hay calificaciones
- Elias, Norbert - Compromiso y Distanciamiento PDFDocumento111 páginasElias, Norbert - Compromiso y Distanciamiento PDFCarola Zenteno SaavedraAún no hay calificaciones
- Alberto Constante-La Filosofia y Las Redes Sociales PDFDocumento75 páginasAlberto Constante-La Filosofia y Las Redes Sociales PDFErin Holmes100% (1)
- El Lenguaje SilenciosoDocumento12 páginasEl Lenguaje SilenciosoMarianAún no hay calificaciones
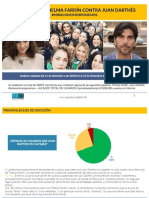
- Analisis Thelma Fardin - Juan DarthesDocumento7 páginasAnalisis Thelma Fardin - Juan DarthesJuan Ignacio AgostoAún no hay calificaciones
- Bienvenidos A CyberiaDocumento22 páginasBienvenidos A CyberiaAna NonantzinAún no hay calificaciones
- Ideas, poder e interdependencia en Eric R. WolfDocumento15 páginasIdeas, poder e interdependencia en Eric R. WolfJaume Estarlich GuiuAún no hay calificaciones
- Fichamiento La Representación Social Un Concepto PerdidoDocumento2 páginasFichamiento La Representación Social Un Concepto PerdidoIgnacio HorminoguezAún no hay calificaciones
- Políticas y Estéticas Del CuerpoDocumento32 páginasPolíticas y Estéticas Del CuerpoZandra PedrazaAún no hay calificaciones
- Varela, F. El Fenomeno de La VidaDocumento468 páginasVarela, F. El Fenomeno de La VidaCarmen SuárezAún no hay calificaciones
- Cuerpo y Ciencia Sociales Enrique ErosaDocumento56 páginasCuerpo y Ciencia Sociales Enrique ErosaAnimalgen100% (10)
- La Formacion de Un Entrevistador - Ronald FraserDocumento17 páginasLa Formacion de Un Entrevistador - Ronald FraserCeleste De MarcoAún no hay calificaciones
- La Narrativa Hipermedia PDFDocumento21 páginasLa Narrativa Hipermedia PDFMariana Cadavid SuarezAún no hay calificaciones
- Bertaux, Daniel (1999)Documento11 páginasBertaux, Daniel (1999)Diego AvaleAún no hay calificaciones
- Conviertíendo en Foucault. Sociogénesis de Un Filosósofo (Reseña)Documento12 páginasConviertíendo en Foucault. Sociogénesis de Un Filosósofo (Reseña)filosofiacontemporaneaAún no hay calificaciones
- Cortina, A. Principales Teorías ÉticasDocumento6 páginasCortina, A. Principales Teorías ÉticasCaterina Flores CantúAún no hay calificaciones
- Barad2003 en EsDocumento32 páginasBarad2003 en EsTomas FontainesAún no hay calificaciones
- Dominación y contienda: Seis estudios de pugnas y transformaciones (1910-2010)De EverandDominación y contienda: Seis estudios de pugnas y transformaciones (1910-2010)Aún no hay calificaciones
- El conocimiento: nuestro acceso al mundo: Cinco estudios sobre filosofía del conocimientoDe EverandEl conocimiento: nuestro acceso al mundo: Cinco estudios sobre filosofía del conocimientoAún no hay calificaciones
- Emociones, poder y conflicto: perspectivas teóricas, género, resistencias y políticas de EstadoDe EverandEmociones, poder y conflicto: perspectivas teóricas, género, resistencias y políticas de EstadoAún no hay calificaciones
- Diccionario de Psicología, Letra F FantasmaDocumento4 páginasDiccionario de Psicología, Letra F FantasmaBellaAnabelleRobyRobeAún no hay calificaciones
- Roig - Arte Impuro Revista Huellas 3Documento12 páginasRoig - Arte Impuro Revista Huellas 3gabAún no hay calificaciones
- Actos de lenguaje y pragmática enDocumento10 páginasActos de lenguaje y pragmática enBellaAnabelleRobyRobeAún no hay calificaciones
- Dialnet Teotihuacan 3212979Documento18 páginasDialnet Teotihuacan 3212979Karen RuizAún no hay calificaciones
- Mirta Varela Del Televisor A La TelevisionDocumento8 páginasMirta Varela Del Televisor A La TelevisionGuido SpinellaAún no hay calificaciones
- Las Joyas de Los AndesDocumento13 páginasLas Joyas de Los AndesBellaAnabelleRobyRobeAún no hay calificaciones
- Sanchidrian, Jose Luis - Manual de Arte Prehistorico - SelecciónDocumento41 páginasSanchidrian, Jose Luis - Manual de Arte Prehistorico - SelecciónBellaAnabelleRobyRobeAún no hay calificaciones
- Empresas Recuperadas de La ArgentinaDocumento8 páginasEmpresas Recuperadas de La ArgentinaBellaAnabelleRobyRobeAún no hay calificaciones
- Rancière - El Espectador EmancipadoDocumento66 páginasRancière - El Espectador Emancipadoceruizsa100% (6)
- Evidencia de Aprendizaje U1 Seguridad PúblicaDocumento10 páginasEvidencia de Aprendizaje U1 Seguridad PúblicaGary HO DiazAún no hay calificaciones
- Psicología Institucional y de Las Organizaciones - Módulo 1Documento29 páginasPsicología Institucional y de Las Organizaciones - Módulo 1Carolina LongaAún no hay calificaciones
- Análisis del volumen de crédito por segmentos otorgados por el sistema financiero privado y popular y solidario en Ecuador 2017-2021Documento12 páginasAnálisis del volumen de crédito por segmentos otorgados por el sistema financiero privado y popular y solidario en Ecuador 2017-2021emilioarthasAún no hay calificaciones
- Ley - de - Cultura Del Edo ZuliaDocumento6 páginasLey - de - Cultura Del Edo ZuliaNUMAN dURAN100% (1)
- Temario ExamenDocumento10 páginasTemario ExamenaileenjaraaileenAún no hay calificaciones
- Dimensión 4Documento8 páginasDimensión 4Miguelina Raquel Maidana de ChaparroAún no hay calificaciones
- Unidad 2 SUJETO HISTORICO 2022Documento10 páginasUnidad 2 SUJETO HISTORICO 2022Diego Silva ArmijoAún no hay calificaciones
- BACKZCO 1999. IMAGINARIOS SOCIALES. Extractos y ActividadDocumento2 páginasBACKZCO 1999. IMAGINARIOS SOCIALES. Extractos y ActividadGuillermo SolisAún no hay calificaciones
- Articulo Tercero GenesisDocumento30 páginasArticulo Tercero GenesisPablo Cesar RamirezAún no hay calificaciones
- Legislacion Deportiva en ColombiaDocumento65 páginasLegislacion Deportiva en ColombiaCristian CamiloAún no hay calificaciones
- Código Ético Del FisioterapeutaDocumento16 páginasCódigo Ético Del FisioterapeutaAndrey OcampoAún no hay calificaciones
- Libro Abierto EDUY21Documento112 páginasLibro Abierto EDUY21Montevideo Portal100% (1)
- Resolucion de Plazas ExcedentesDocumento3 páginasResolucion de Plazas ExcedentesRodolfo Cahuana QuichcaAún no hay calificaciones
- Programa Maestría CEHSEUDocumento68 páginasPrograma Maestría CEHSEUPável AlemánAún no hay calificaciones
- América de Cali S.A. en ReorganizaciónDocumento26 páginasAmérica de Cali S.A. en ReorganizaciónJuan CantilloAún no hay calificaciones
- GranovetterDocumento8 páginasGranovetterGuillermo Zuñiga UmanzorAún no hay calificaciones
- SsssssssssssssssssssssssssssssssssssssssssssssssssssssssssDocumento14 páginasSsssssssssssssssssssssssssssssssssssssssssssssssssssssssssLucero SilvaAún no hay calificaciones
- Dimensiones en La Práctica DocenteDocumento8 páginasDimensiones en La Práctica DocenteLex AlivadAún no hay calificaciones
- Instituciones e Historia Economica (North)Documento25 páginasInstituciones e Historia Economica (North)john e mejíaAún no hay calificaciones
- Abraxas en La Encrucijada Del Bien y Del MalDocumento204 páginasAbraxas en La Encrucijada Del Bien y Del MalMiguel DrumsAún no hay calificaciones
- Equipo DirecciónDocumento6 páginasEquipo DirecciónTransgenicos CultivaAún no hay calificaciones
- 21Documento129 páginas21Nicolas212Aún no hay calificaciones
- Ley Educacion MorelosDocumento46 páginasLey Educacion Morelosesther_calvo5447Aún no hay calificaciones
- Funciones Del ResumenDocumento4 páginasFunciones Del ResumenDoreilys Cuarez Armas100% (1)
- Libro DesplazamientoDocumento88 páginasLibro DesplazamientoChocó Siete Días SemanarioAún no hay calificaciones
- Convenio de Devengación 2021 SuscritoDocumento5 páginasConvenio de Devengación 2021 SuscritoAlejo ChambaAún no hay calificaciones
- Plan de mantenimiento ISUSDocumento6 páginasPlan de mantenimiento ISUSSantiago GuilcazoAún no hay calificaciones