{kind=link}
Implementation of NetAdapt
This code is based on pytorch (version 1.0.1).
However, since pytorch does not handle 32bits architectures and that the goal I had in mind when implementing the paper was to do efficient inference on a rasberry-pi,
I used tensorflow lite to compute the tables instead (compute_table.py).
This means that two environments (one with pytorch and scikit learn and one with tensorflow 1.13.1 (or one environment with both) are needed to run the project.
The code uses CIFAR-10 as a dataset.
The performances tables are built in two steps. First, all the .tf-lite files are built on a Desktop computer. This takes approximately one day (without multiprocessing) and generates a few gigs worth of .tflite files. The script do not uses multiprocessing on its own but it offers an argument to specify the number of times it was launched in parallel and one for the offset of the current instance so that it only does a fraction of the work.
Once this is done, the files can be used to generate measurements on the target device. We found out averaging several of them and smooting to give better results, see this report Section 4.5 for an explanation and perf_tables/merge_perf_tables for an example using scipy.
To build a table, one would need to use these lines (4 processes might not be the optimum)
python compute_table.py --save_file='res-40-2-tf-lite-pred' --mode='save' --output_folder='tflite_files' --num_process=4 --offset_process=0
python compute_table.py --save_file='res-40-2-tf-lite-pred' --mode='save' --output_folder='tflite_files' --num_process=4 --offset_process=1
python compute_table.py --save_file='res-40-2-tf-lite-pred' --mode='save' --output_folder='tflite_files' --num_process=4 --offset_process=2
python compute_table.py --save_file='res-40-2-tf-lite-pred' --mode='save' --output_folder='tflite_files' --num_process=4 --offset_process=3
on the desktop computer/server, compute_table uses a WideResNet-40-2 by default.
Then, on the target device having a
python compute_table.py --save_file='res-40-2-tf-lite-pred' --mode='load' --output_folder='tflite_files' --benchmark_lite_loc='path_towards_tf_lite_benchmark_binary'
We recommend to repeat this step and then to use a script analogous to perf_tables/merge_perf_tables. perf_tables/res-40-2-tf-lite-raspberry-pi.pickle is an example of the resulting file.
A slight modification w.r.t. the paper is that we do not prune the layers with smallest error increase but the one with smallest relative error increase (
First, the base network needs to be built,
python train.py --net='res' --depth=40 --width=2.0 --save_file='res-40-2'
would train a base WideResNet-40-2 for example (assuming CIFAR-10 location is in ~/Documents/CIFAR-10)
Then, the network can be pruned, for example
python prune.py --save_file='res-40-2-pruned' --pruning_fact=0.4 --base_model='res-40-2' --perf_table='res-40-2'
would prune 40% of the res-40-2 network using res-40-2 (assumed to lay in folder perf_tables) as a performance table.
Unfortunately, the network objects used in this script are non trivial to implement (see model/wideresnet.py and utils/compute_table/wideresnet_table.py) for example. I only built a wideresnet. Networks with skip connections are harder to code because it is needed to share the number of channels between all the layers connected through skip connections, models without skip connections would be simpler to code.
I implemented NetAdapt as a part of my master thesis. This is only a cured repo. During my thesis, I found out that training the network from scratch after pruning is much more interesting than fine-tuning it as advocated by A Closer Look at Structured Pruning for Neural Network Compression . MobileNetv3 also retrained from scratch after pruning when using NetAdapt. After pruning, we save the number of channels pruned per layers that can be used to retrain WideResNets from scratch. I do not provide files to do so here but I used this in pytorch and this in keras (tensorflow) to get retrained from scratch networks.
Unfortunately, pruning results are somewhat deceiving, at least on CIFAR-10 on a Raspberry PI 3B using a WideResNet as a base architecture. We do not do better than uniform pruning and we actually do worse than finiding new architectures with a grid search.
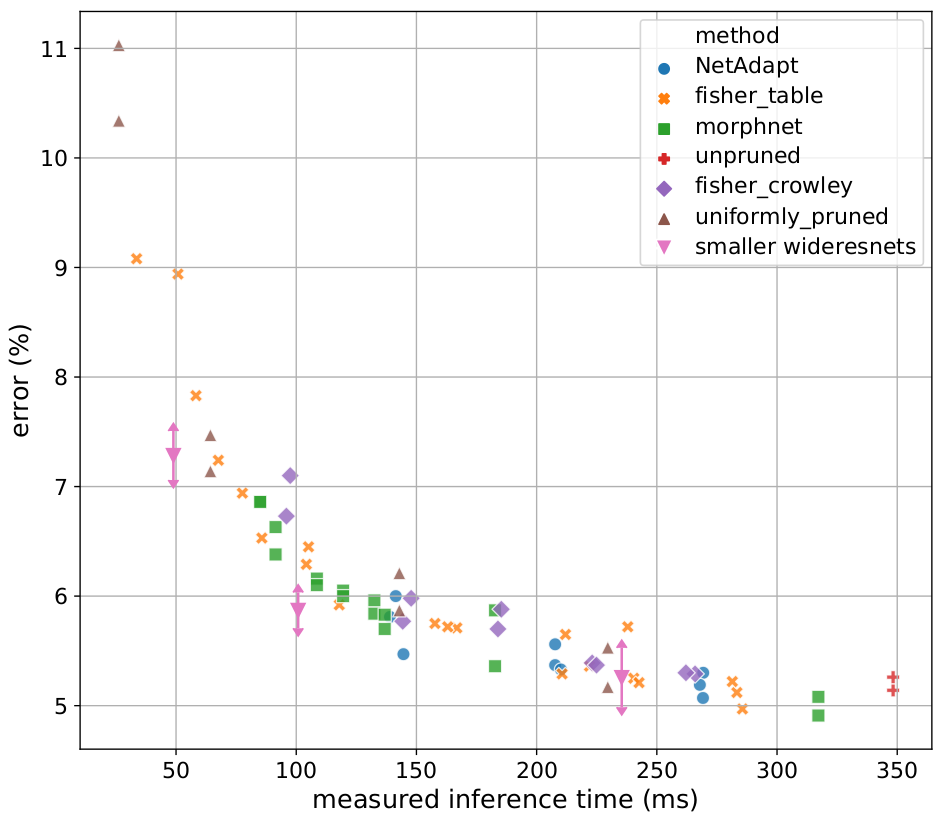
More details on this can be found in my master thesis report, Sections 4.8 and 4.6.