
An estimated 463 exabytes of data will be produced each day by the year 2025. Data scientists will need to make sense out of this data. Obviously, you can’t process, nor store big data on any single computer. Big data needs to be stored in a cluster of computers.
This makes the machine learning process more complex. Luckily, there are tools that were built specifically for dealing with big data. Apache Spark is one of those tools.
Let’s take a look at how you can use Apache Spark to process big data.
What is Apache Spark?
Apache Spark is an open-source engine for analyzing and processing big data. A Spark application has a driver program, which runs the user’s main function. It’s also responsible for executing parallel operations in a cluster.
A cluster in this context refers to a group of nodes. Each node is a single machine or server. A unit of work sent to the executor is known as a task, and a parallel computation involving multiple tasks is known as a job.

The SparkContext
Applications in Spark are controlled by the SparkContext. It connects to the cluster manager, as you can see in the diagram above. There are several cluster managers, namely:
- Spark’s own standalone cluster manager
- Mesos
- YARN
The cluster manager allocates resources to Spark applications.
Spark executors
Executors live on the worker node, and they run computations and store your application’s data. Worker nodes are responsible for running application code in the cluster.
Every application in Spark will have its own executor. SparkContext sends tasks to the executor. Applications are isolated from each other, because every application has its own executor program.
Why use Apache Spark
There are other tools, like Hadoop, that can be used for distributed computing. Why would you use Apache Spark?
- it’s 100 times faster than Hadoop thanks to in-memory computation
- Apache Spark can be used in Java, Scala, Python, R, or SQL
- you can run Apache Spark on Hadoop, Apache Mesos, Kubernetes, or in the cloud
Apache Spark installation
It’s expected that you’ll be running Spark in a cluster of computers, for example a cloud environment. However, if you’re a beginner with Spark, there are quicker alternatives to get started. Let’s take a look at some of them.
Setting up Spark on Google Colab
To run Spark on Google Colab, you need two things: `openjdk` and `findspark`.
`findspark` is the package that makes Spark importable on Google Colab. You will also need to download Spark and extract it.
!apt-get install openjdk-8-jdk-headless -qq > /dev/null
!wget -q https://www-us.apache.org/dist/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgz
!tar xf spark-3.0.1-bin-hadoop2.7.tgz
!pip install findspark
Next step, set some environment variables based on the location where Spark and Java were installed.
import os
os.environ["JAVA_HOME"] = "/usr/lib/jvm/java-8-openjdk-amd64"
os.environ["SPARK_HOME"] = "/content/spark-3.0.1-bin-hadoop2.7"
Next, use `findspark` to make Spark importable.
import findspark
findspark.init()
You need to create the `SparkContext` any time you want to use Spark. Create an instance of the `SparkContext` to confirm that Spark was installed successfully.
import pyspark
sc = pyspark.SparkContext()
Installing Apache Spark on your local machine
How can you install Spark on your local machine? This process can get very complicated, very quickly. It might not be worth the effort, since you won’t actually run a production-like cluster on your local machine.
It’s just easier and quicker to use a container to run Spark’s installation on your local machine. You will need to have Docker installed in order to install Spark using a container.
The next step is to pull the Spark image from Docker Hub. Once this is done, you will be able to access a ready notebook at localhost:8888.
$ docker run -p 8888:8888 jupyter/pyspark-notebook
When you navigate to the Notebook, you can start a new SparkContext to confirm the installation.
import pyspark
sc = pyspark.SparkContext()

Running Apache Spark on Databricks
The most hassle-free alternative is to use the Databricks community edition. The only thing you need to do is set up a free account. This article will assume that you’re running Spark on Databricks. However, all the other alternatives we mentioned will suffice.

Apache Spark basics
The most fundamental thing to understand in Apache Spark is how it represents data. The main representations are:
- Resilient Distributed Datasets (RDDs)
- Dataframes
Resilient Distributed Datasets (RDDs)
A Resilient Distributed Datasets (RDD) is a fault-tolerant collection of elements that can be operated on in parallel. RDDs automatically recover from faults. This format is a great choice when:
- you’re working with unstructured data, such as media or text streams
- you need to perform low-level transformations on a dataset
RDD creation
You can create an RDD by parallelizing a collection from the driver program, or by using a dataset in the file system. Spark will determine the optimal number of partitions for splitting the dataset. However, you can pass this as the second argument to the `parallelize` function:
my_list = [1, 2, 3, 4, 5,6]
my_list_distributed = sc.parallelize(my_list,3)
RDD operations
In Spark there are two main type of operations:
- transformations
- actions
Spark transformations
Transformations will create a new dataset from one that already exists. An example of this operation is `map`. Transformations are lazy, meaning that they don’t return the result of their computation right away. Computation only happens when an action requests for the result.
my_list = [2,3,4,5,6]
def power_two(x):
return x**2
list(map(power_two,my_list))

Other transformations in Spark include:
- `filter` – returns a dataset after selecting items that return true on a certain condition
- `union` – returns the union of two datasets
Spark actions
An action will return a value after a certain computation on the dataset. For example, the `reduce` function.
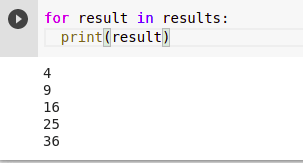
results = map(power_two,my_list)
for result in results:
print(result)
There are a couple of other actions that you can perform with Spark:
- `collect` to return the dataset as an array
- `count` to return the number of items in a dataset
- `take(n)` to return the first n elements of a dataset
- `first` to return the first element in a dataset
RDD persistence
Spark allows you to improve the performance of your application by caching your dataset. Computations can be saved in memory and retrieved from the cache the next time they’re needed. Caching in Spark is fault-tolerant, so any partitions that are lost will be recomputed using the transformations that created them.
df.cache()
Dataframes
Spark Dataframes are immutable, and very similar to Pandas DataFrames. As you’ll see later, Spark DataFrames can be queried using SQL. You will see the usage of DataFrames and SQL in Spark as you go through the machine learning example below.
READ ALSO
Machine Learning in Spark
You can do machine learning in Spark using `pyspark.ml`. This module ships with Spark, so you don’t need to look for it or install it. Once you log in to your Databricks account, create a cluster. The notebook that’s needed for this exercise will run in that cluster.
When your cluster is ready, create a notebook. Next, you will need to define the source of your data. Databricks lets you upload the data or link from one of their partner providers. When uploading the data, it needs to be less than 2GB.

For the sake of illustration, let’s use this heart disease dataset from UCI Machine Learning.
Data exploration with Spark
Note the path to your dataset once you upload it to Databricks so that you can use it to load the data. Also, make sure your notebook is connected to the cluster.

df = spark.read.csv('/FileStore/tables/heart.csv',sep=',',inferSchema='true',header='true')
Notice that you didn’t have to create a SparkContext. This is because Databricks does this for you by default. You can type `sc` on a cell to confirm that.

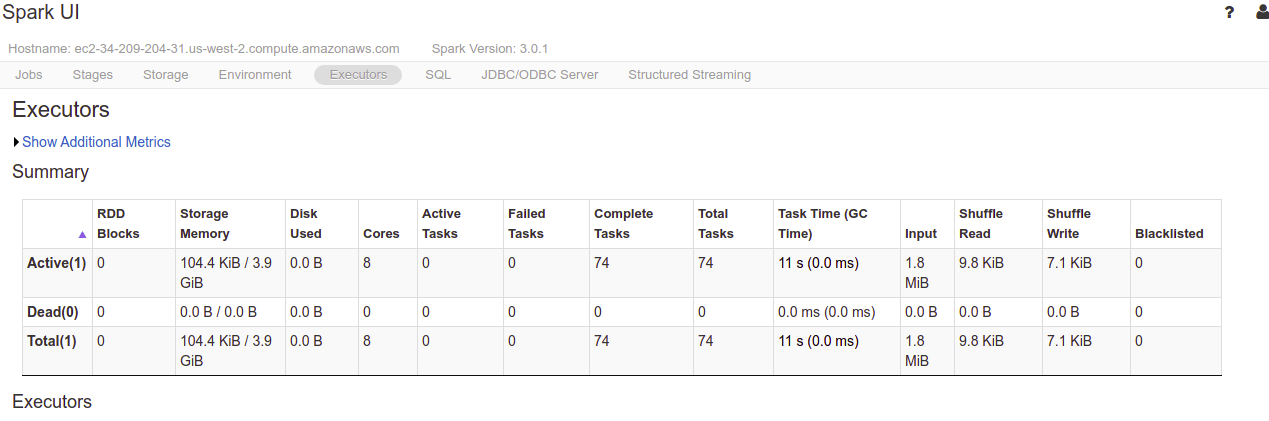
You can also click the link to the Spark UI to see more information about your cluster.
The quickest way to run data exploration on Databricks is to use the `display(df)` function. This function is unique to Databricks so it will not work if you’re on Google Colab or your local machine. On those platforms you can use:
df.display()

Clicking on the plot options button will give you more charts and options that you can try. You can download the plots as well.
As mentioned before, you can run filter operations.
df.filter((df.age>20) & (df.target=='1')).show()

Spark also lets you run `group by` operations similarly to how you would do them in Pandas. Let’s see how that can be done.
from pyspark.sql import functions as F
df.groupBy(["sex"]).agg(
F.mean("age").alias("Mean Age")
).show()

If you’re coming from the world of SQL, you might be interested in querying the data frame as if it was an SQL table. You can do that by using the `SQLContext` to register a temporary SQL table. After that, you can run SQL queries normally.
from pyspark.sql import SQLContext
sqlContext = SQLContext(sc)
df.registerTempTable('df_table')
df_sql = sqlContext.sql('select age,target,sex,slope,cp from df_table where age>30 ORDER BY age DESC')
df_sql.show()

Data preprocessing with Spark
Once you’re done with data exploration, the next step is to convert the data into a format that would be accepted by Spark’s MLlib. In this case, the features need to be transformed into a single vector that will be passed to the machine learning model.
This can be done using the `VectorAssembler`. Let’s import it and instantiate it using the features in the dataset.
from pyspark.ml.feature import VectorAssembler
feat_cols = ['age',
'sex',
'cp',
'trestbps',
'chol',
'fbs',
'restecg',
'thalach',
'exang',
'oldpeak',
'slope',
'ca',
'thal']
vec_assember = VectorAssembler(inputCols = feat_cols, outputCol='features' )
The next step is to use it to transform the data frame.
final_data = vec_assember.transform(df)
The `take` function can be used to view a part of the dataset. You will notice a vector known as `features` that contains all the features.
final_data.take(2)

Next, split the dataset into a training and testing set.
training,testing = final_data.randomSplit([0.7,0.3],seed=42)

Building the Machine Learning model with PySpark MLlib
The next step is to fit this dataset to the algorithm. Let’s use Logistic Regression here.
Start by importing it. You can access more algorithms here.
from pyspark.ml.classification import LogisticRegression
Let’s create an instance of the algorithm while passing the label column name and the name of the features.
lr = LogisticRegression(labelCol='target',featuresCol='features')
Now fit the model to the training set.
lrModel = lr.fit(training)
Evaluating the model
Prior to evaluating the model you have to run the predictions. Use the `transform` function.
predictions = lrModel.transform(testing)
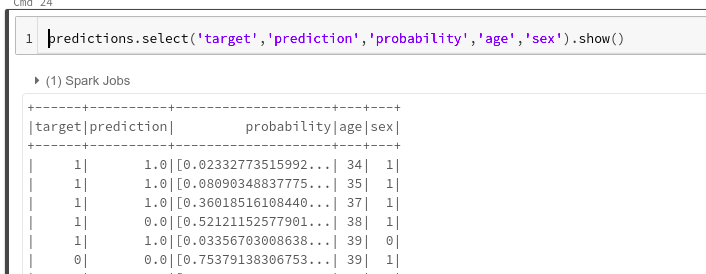
You can view these predictions by selecting some columns.
predictions.select('target','prediction','probability','age','sex').show()
Since this is binary classification, the `BinaryClassificationEvaluator` function can be used to evaluate the model.
from pyspark.ml.evaluation import BinaryClassificationEvaluator
evaluator.evaluate(predictions)

Serving Apache Spark Machine Learning models
Databricks lets you serve your machine learning models with MLflow. However, the easiest way to serve your model is to send it to a model registry like Neptune.
Final thoughts
In this article, you’ve seen that Apache Spark can be used for analyzing and building machine learning models for handling big data. We also covered the core concepts of using Apache Spark:
- what Apache Spark is
- data representations in Apache Spark
- various methods for installing Apache Spark
- running Spark on Databricks, your local machine, and on Google Colab
- building and saving machine learning models using Apache Spark
You’re now armed with the skills you need to explore and build machine learning models using big data. Thanks for reading!
