![]()
Azure Data Engineers apply their knowledge to identify and meet data requirements. They design and implement solutions. They also manage, monitor, and ensure the security and privacy of data using Azure services like Azure synapse analytics and Azure Data Lake. We have recently started our Azure Data Engineer [DP-203] Training Program.
In this post, we will be sharing the Day 1 live session review with the FAQs of Azure Data Engineering [DP-203] Day 1 Training which will help you in understanding some basic concepts.
Out of which, in the Day 1 Live Session of the Training Program, we covered the concepts of Compute Storage Data Engineering
>Basic Data Terminologies
Q2: Why do we need a Data Warehouse if we have a Database?
Q3: How do we convert data from a Database to a Data Warehouse?
Also, Read Our blog post on ADF Interview Questions.
> Module 1: Get started with data engineering on Azure.
So, here are some of the DP-203 Questions and Answers asked during the Live session from Module 1: Get started with data engineering on Azure.
Q1. What is Azure Synapse Spark?
A. Azure Synapse Spark, known as Spark Pools, is based on Apache Spark and provides tight integration with other Synapse services. Just like Databricks, Azure Synapse Spark comes with a collaborative notebook experience supported interaction and.NET developers once more have something to cheer about with.NET notebooks supported out of the box.
Q2. What is the Synapse link?
A. Microsoft recently launched Azure Synapse Link. Available in Azure Cosmos DB, it’s a cloud-native implementation of hybrid transaction/analytical processing (HTAP). It will soon be available in other operational database services such as:
1. Azure SQL
2. Azure Database for PostgreSQL
3. Azure Database for MySQL
Azure Synapse Link eliminates the barriers and tightly integrates Azure operational database services and Azure Synapse Analytics. It facilitates no Extract-Transform-Load (ETL) analytics in Azure Synapse Analytics against your operational data at scale.
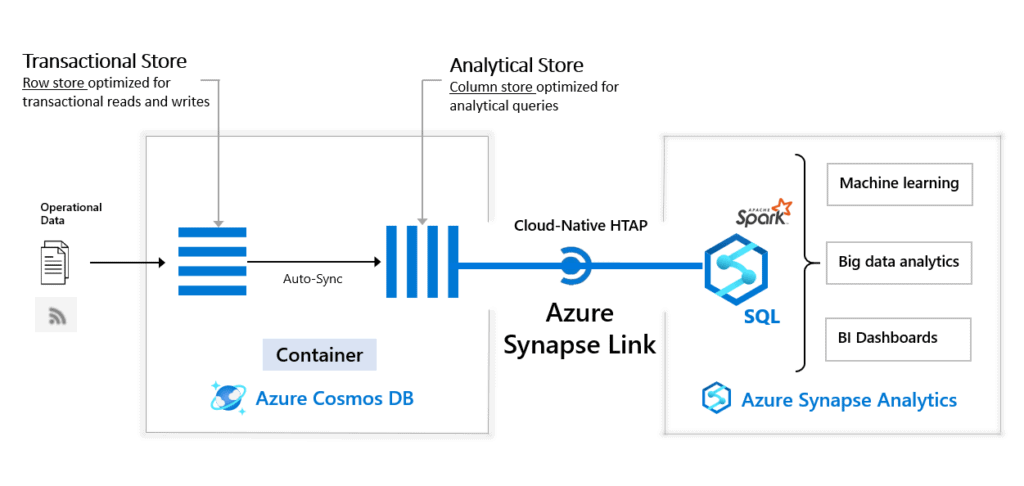 Source: Microsoft
Source: Microsoft
Q3. Azure data bricks is a processing engine with the help of Apache Spark.
A. Azure Databricks is the implementation of Apache Spark on Azure. With fully managed Spark clusters, it’s wont to process large workloads of knowledge and also helps in data engineering, data exploring, and also visualizing data using Machine learning.
Q4. What is Delta Lake? How is it different from Data Lakes?
A. Azure Data Lake usually has multiple data pipelines reading and writing data concurrently. It’s hard to stay data integrity thanks to how big data pipelines work (distributed writes which will be running for an extended time). Delta Lake may be a new Spark functionality released to unravel exactly this. Delta lake is an open-source storage layer from Spark that runs on top of an Azure Data Lake. Its core functionalities bring reliability to the large data lakes by ensuring data integrity with ACID transactions while at an equivalent time, allowing reading and writing from/to the same directory/table. ACID stands for Atomicity, Consistency, Isolation, and Durability.
Q5. What are bronze, silver, and gold tables in delta lake architecture?
A. we organize our data into layers or folders as defined as bronze, silver, and gold as follows:
1-Bronze – tables contain raw data ingested from various sources (JSON files, RDBMS data, IoT data, etc.).
2-Silver – tables will provide a more refined view of our data. We can join fields from various bronze tables to enrich streaming records or update account statuses based on recent activity.
3-Gold – tables provide business-level aggregates often used for reporting and dashboarding. 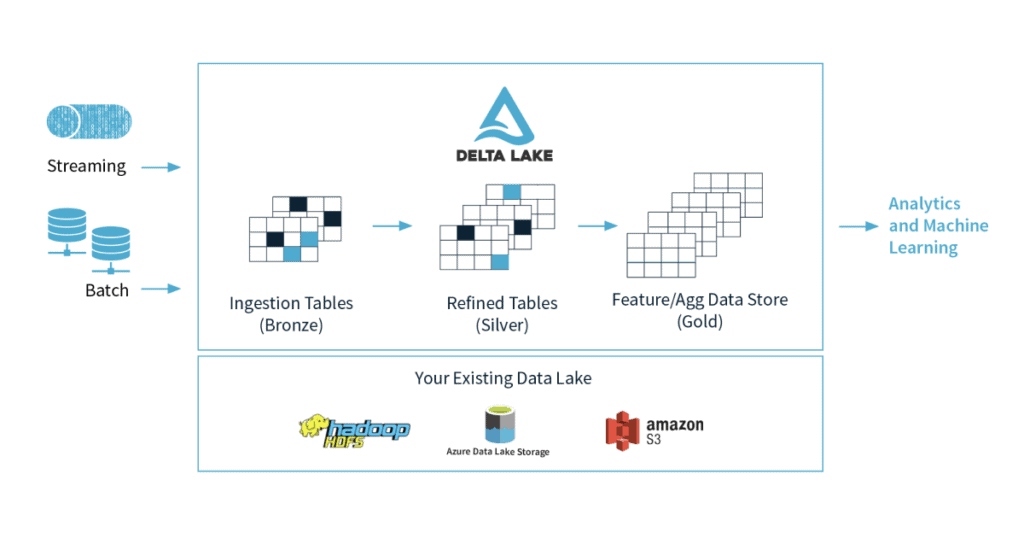 Source: Microsoft
Source: Microsoft
Q6. What are covering indexes?
A. A covering index is a special case of an index in InnoDB where all required fields for a query are included in the index; in other words, the index itself contains the specified data to execute the queries without having to execute additional reads.
Q7. How is Azure SQL different from Synapse SQL?
A. Azure SQL Database: a part of the Azure SQL family, Azure SQL Database is an intelligent, scalable, electronic database service built for the cloud. Optimize performance and sturdiness with automated, AI-powered features that are always up so far. With serverless computing and Hyperscale storage options that automatically scale resources on-demand, you’re liberal to specialize in building new applications without fear about storage size or resource management.
Azure Synapse SQL: Azure Synapse SQL is a big data analytic service that permits you to query and analyze your data using the T-SQL language. You can use the quality ANSI-compliant dialect of SQL language used on SQL Server and Azure SQL Database for data analysis. Transact-SQL language is employed in a serverless SQL pool and a dedicated model can reference different objects and has some differences within the set of supported features.
Q8: Which is cheaper, Blob or Gen2 storage? Which one is used more frequently, or does it not matter and we can choose either?
A: Blob Storage and Azure Data Lake Storage Gen2 have different pricing models. The choice depends on your specific requirements and usage patterns
Q9. Is Cosmos DB a semi-structured database?
A. Azure Cosmos DB is a fully managed NoSQL database service for contemporary app development. NoSQL stands for Not Only SQL. The main meaning of the NoSQL databases is an alternative to SQL databases and can perform all types of query operations like any RDBMS database like Microsoft SQL Server. Mainly NoSQL contains all databases which aren’t a neighborhood of the normal management systems (RDBMS). The main purpose of the NoSQL database is a simple design, the likelihood of both horizontal and vertical scaling, and in particular, easy operational control over the available data. NoSQL database breaks the normal arrangement of the electronic database and provides a chance for the developer to store the info into the database as same as their programming requirements. In simple words, the NoSQL database is often implemented in such a way that traditional databases couldn’t be structured.
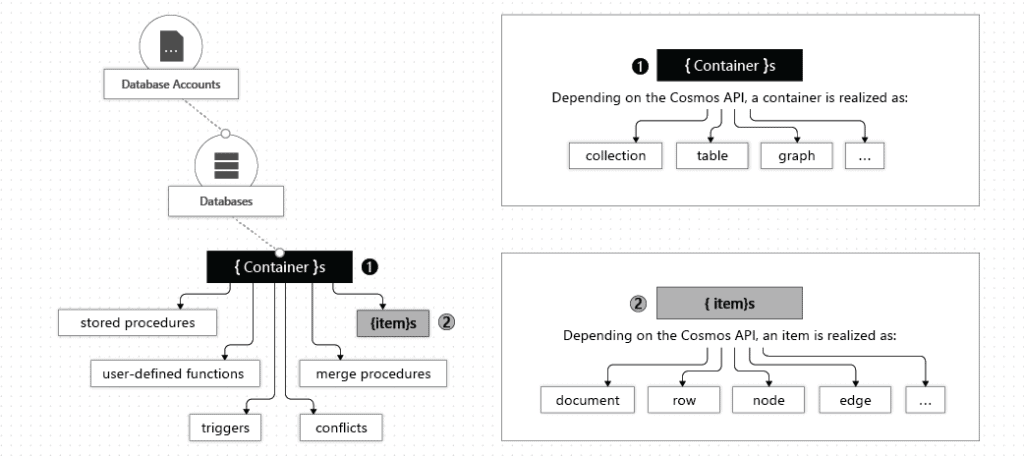
Source: Microsoft
Q10. Are Hyperspace and MSSparkUtil proprietary for the Synapse platform? Or can we use it in AZURE Databricks or AWS Databricks OR even in the Google Databricks platform?
A. Hyperspace, an indexing subsystem for Apache Spark, is now open source and can be used with any platform. Whereas Microsoft Spark Utilities (MSSparkUtils) is a built-in package to help you easily perform common tasks. You can use MSSparkUtils to figure out file systems, to urge environment variables, and to figure out secrets.
Q11. What is a processing engine?
A. A processing engine is a tool that has to compute power to process data and give output.
Q12. What is the difference between Apache Spark for Synapse and Apache Spark?
A: Apache Spark for Synapse is Apache Spark with added support for integrations with other services (AAD, AzureML, etc.) and extra libraries (mssparktuils, Hummingbird) and pre-tuned performance configurations. Any workload that’s currently running on Apache Spark will run on Apache Spark for Azure Synapse without change.
Q13. What is an example of quasi structured data structure?
A. An example of quasi-structured data is the data about web pages a user visited and in what order.
Structured vs Unstructured vs Semi-Structured.
 Source: Microsoft
Source: Microsoft

Q14. What are streaming and batch processing?
A. Under the batch processing model, a set of data is collected over time, then fed into an analytics system. In other words, you collect a batch of information, then send it in for processing. Under the streaming model, data is fed into analytics tools piece by piece. The processing is usually done in real time.
Q15. How concurrency and locking are getting performed when multiple users write on streams?
A. Delta Lake uses optimistic concurrency control to provide transactional guarantees between writes. Under this mechanism, writes operate in three stages:
Read=> Reads (if needed) the latest available version of the table to identify which files need to be modified (that is, rewritten).
Write=> Stages all the changes by writing new data files.
Validate and commit=> Before committing the changes, checks whether the proposed changes conflict with any other changes that may have been concurrently committed since the snapshot that was read. If there are no conflicts, all the staged changes are committed as a new versioned snapshot, and the write operation succeeds. However, if there are conflicts, the write operation fails with a concurrent modification exception rather than corrupting the table as would happen with the write operation on a Parquet table. The isolation level of a table defines the degree to which a transaction must be isolated from modifications made by concurrent operations. For information on the isolation levels supported by Delta Lake on Databricks, see Isolation levels.
Q16. What is fault tolerance?
A. Fault tolerance refers to the ability of a system (computer, network, cloud cluster, etc.) to continue operating without interruption when one or more of its components fail. The objective of creating a fault-tolerant system is to prevent disruptions arising from a single point of failure, ensuring the high availability and business continuity of mission-critical applications or systems.
Q17. What are Cubes?
A. An OLAP cube, also known as a multidimensional cube or hypercube, is a data structure in SQL Server Analysis Services (SSAS) that is built, using OLAP databases, to allow a near-instantaneous analysis of data.
Q18. Is serverless the same as built-in?
A. Yes
Q19. How data is mounted in storage?
A. A mount point is a directory in a file system where additional information is logically connected from a storage location outside the operating system’s root drive and partition. … For instance, in data storage, to mount is to place a data medium on a drive in a position to operate.
Q20. How can I force Hyperspace to use my index? Is there a way to do that?
A. Hyperspace provides commands to enable and disable index usage. Using the “enableHyperspace” command, existing indexes become visible to the query optimizer and Hyperspace would exploit them, if applicable to a given query. By using the “disableHyperspace” command, Hyperspace will no longer consider using indexes during query optimization.
Q21. What is IoT?
A. The Internet of Things, or IoT, refers to the billions of physical devices around the world that are now connected to the Internet, all collecting and sharing data. Thanks to the arrival of super-cheap computer chips and the ubiquity of wireless networks, it’s possible to turn anything, from something as small as a pill to something as big as an airplane, into a part of the IoT.
Q22. Are Azure Synapse Analytics and Azure Databricks competing products?
A. Azure Synapse Analytics is a limitless analytics service that brings together data integration, enterprise data warehousing, and big data analytics. It gives you the freedom to query data on your terms, using either serverless or dedicated resources—at scale. Azure Synapse brings these worlds together with a unified experience to ingest, explore, prepare, manage, and serve data for immediate BI and machine learning needs.
Azure Databricks provides the latest versions of Apache Spark and allows you to seamlessly integrate with open-source libraries. Spin up clusters and build quickly in a fully managed Apache Spark environment with the global scale and availability of Azure. Clusters are set up, configured, and fine-tuned to ensure reliability and performance without the need for monitoring.
 Q23.What is the difference between Synapse Pipelines and Synapse Studio?
Q23.What is the difference between Synapse Pipelines and Synapse Studio?
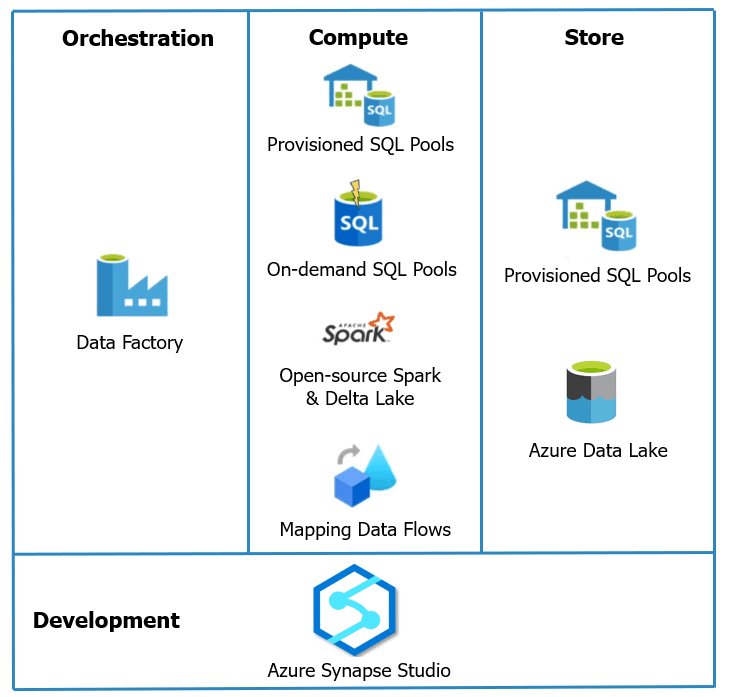
A. We use Synapse Studio to access all of these capabilities like synapse pipelines, synapse links, etc. through a single Web UI in which one of the services is synapse pipelines which are used for data integration and can be accessed using Synapse Studio.
Q24. Can we replace Synapse pipelines with other ETL like Talend or SSIS?
A. We can use both Azure data factory or Synapse with Synapse Pipelines, Data Integration & Orchestration to integrate our data and operationalize all our code development.
Q25.Do we have a Synapse Link option available for Azure SQL Database?
A. Azure Synapse Link is available for Azure Cosmos DB SQL API containers or for Azure Cosmos DB API for MongoDB collections. Use the following steps to run analytical queries with the Azure Synapse Link for Azure Cosmos DB: Enable Synapse Link for your Azure Cosmos DB accounts.
Q26.Difference between Synapse SQL, Azure SQL DB, and Cosmos DB?
A. Microsoft Azure Synapse Analytics
Elastic, large-scale data warehouse service leveraging the broad eco-system of SQL Server primary database model is relational DBMS.
Microsoft Azure SQL DB
Most Transact-SQL features that applications use are fully supported in both Microsoft SQL Server and Azure SQL Database. For example, the core SQL components like data types, operators, string, arithmetic, logical, and cursor functions work identically in SQL Server and SQL Database.
Microsoft Azure Cosmos DB
Globally distributed, horizontally scalable, multi-model database service and primary database model is Document store, Graph DBMS, key-value store, and Wide column store.
Q27. In Synapse SQL We have Built-in Pool and Dedicated Pool. explain scenarios to go for a built-in and dedicated pool.
A. The goal of using Dedicated SQL Pools is to store data on a massive scale with the ability to query efficiently. This is easier since it’s stored in a columnar format, and you’ll leverage clustered column store indexing for fast retrieval. A serverless SQL pool enables you to analyze your Big Data in seconds to minutes, depending on the workload. … If you employ Apache Spark for Azure Synapse in your data pipeline, for data preparation, cleansing, or enrichment, you’ll query external Spark tables you’ve created within the process, directly from a serverless SQL pool.
Q28. ETL should always happen with Azure Data Factory or Synapse Pipelines, or can we use any other ETL tool in the market?
A. Along with Azure Data Factory and Synapse Pipelines, you can also use data bricks. Data Integration & Orchestration to integrate your data and operationalize all of your code development with Synapse Pipelines.
Q29. Performance Using SQL vs Spark in Azure Databricks?
A. Azure Databricks is an Apache Spark-based big data analytics service designed for data science and data engineering offered by Microsoft. It allows collaborative working also as working in multiple languages like Python, Spark, R, and SQL. Working on Databricks offers the benefits of cloud computing – scalable, lower cost, on-demand processing, and data storage.
Q30. Indexing with Hyperspace is in-memory?
A. In Hyperspace, note that there is no separate “indexing service” required as a prerequisite, since the indexing infrastructure, in principle, can leverage any available query engine (e.g., Spark) for index construction. And since indexes and their metadata are stored on the info lake, users can parallelize index scans to the extent that their query engine scales and their environment/business allows. Index metadata management is another important part of the indexing infrastructure. Internally, index metadata maintenance is managed by an index manager. The index manager takes charge of index metadata creation, update, and deletion when corresponding modification happens to the index data, and thus governs consistency between index data and index metadata. The index manager also provides utility functions to read the index metadata from its serialized format. For example, the query optimizer can read all indexed metadata and then find the best index for given queries.
Q31: Can you provide more information on serverless SQL?
A: Serverless SQL refers to Azure SQL Database serverless, which automatically scales compute resources based on demand, providing a cost-effective and flexible way to run SQL queries without managing infrastructure.
Q32. What is a hierarchical namespace?
A. We need to enable the Hierarchical namespace to enable data lake storage gen, if not it will be normal blob storage. In hierarchy, we can create subfolders but we cannot create subfolders in blob storage.
Q33. Brief introduction about HIVE?
A. Apache Hive is an open-source data warehouse software for reading, writing, and managing large data set files that are stored directly in either the Apache Hadoop Distributed File System (HDFS) or other data storage systems such as Apache HBase.
Q34. Was it possible before Delta Lake architecture to query unstructured data from Data lakes?
A. Data Lake is Massively scalable and built to the open HDFS standard. With no limits to the dimensions of knowledge and therefore the ability to run massively parallel analytics, you’ll now unlock value from all of your unstructured, semi-structured, and structured data.
Q35.Delta Lake is not really a tool or service developed by Microsoft but you are using Azure tools to create delta lake?
A. The common misconception made about Delta Lake is that people think it is a data platform service. It’s not. It is simply a format that’s defined once you create a Data Frame against the storage layer, and this is often what brings the ACID capabilities to the info held in the Data Frames.
Q 35. What is predicate push-down?
A: Predicate push-down is an optimization technique to process only the required data and can be applied to Spark Queries by defining filters in where conditions.
Q 36. How does it Optimize?
A: Predicate Push downs limit the number of files and partitions that Spark reads while querying, thus reducing disk I/O. Also querying on data in buckets with predicate push-downs produce results faster with less shuffle.
Q 37. What are the different types of joins in DataBricks?
A. There are 4 types of joins in Databricks. They are static-static join, stream-static join, static-stream join, and stream-stream join.
Q 38. Does Delta Lake Arch have the capability to process batch data?
A. Yes, delta lake has the capability to process batch and stream data.
Q 39. does Delta Lake architecture use Databricks to replace the traditional Azure data processing architecture (ingestion, ADF processing, SQL, Power BI) usage?
A. Databricks is an alternate method to develop pipelines using PySpark. This is not a replacement.
Q 40. What is schema evolution in Delta Lake?
A. Schema evolution is a feature that allows users to easily change a table’s current schema to accommodate data that is changing over time. Most commonly, it’s used when performing an append or overwrite operation, to automatically adapt the schema to include one or more new columns.
Q 41. What is fault tolerance?
A. Fault tolerance refers to the ability of a system (computer, network, cloud cluster, etc.) to continue operating without interruption when one or more of its components fail. The objective of creating a fault-tolerant system is to prevent disruptions arising from a single point of failure, ensuring the high availability and business continuity of mission-critical applications or systems.
Q 42: Will a free Azure subscription allows us to complete all the labs in this course?
Q 43: Can you become a data engineer without being a data analyst?
A: No, being a data analyst is not a requirement to become a data engineer. Both roles have distinct responsibilities and skill sets.
Q 44: What are the differences between IAAS, PAAS, and SAAS?
A: IAAS (Infrastructure as a Service) provides virtualized computing resources, PAAS (Platform as a Service) offers a platform for developing and deploying applications, and SAAS (Software as a Service) delivers software applications over the Internet.
Q45: Is a star schema characterized by facts in the middle and dimensions surrounding them?
A: Yes, in a star schema, the central fact table is connected to multiple-dimension tables, forming a star-like structure.
Q46: Are there other data visualization tools that can be integrated with Azure?
A: Yes, Azure supports various data visualization tools, including Power BI, Tableau, and QlikView, which can be integrated to create insightful visualizations.
Q47: What does it mean to have resource access on your subscription?
A: Having resource access on your subscription means having permissions and privileges to manage and utilize the resources (such as virtual machines, databases, and storage accounts) within that Azure subscription.
Feedback Received…
Here is some positive feedback from our trainees who attended the session:
Read more about the DP-203 Certification and whether it is the right certification for you, from our blog on Exam DP-203: Data Engineering on Microsoft Azure
Quiz Time (Sample Exam Questions)!
Comment with your answer & we will tell you if you are correct or not!
References
- Exam DP-203: Data Engineering on Microsoft Azure
- Microsoft Certified Azure Data Engineer Associate | DP 203 | Step By Step Activity Guides (Hands-On Labs)
- Azure Data Engineer vs Data Scientist vs Database Administrator vs Data Analyst
Next Task For You
In our Azure Data Engineer training program, we will cover 28 Hands-On Labs. If you want to begin your journey towards becoming a Microsoft Certified: Azure Data Engineer Associate by checking out our FREE CLASS.


Leave a Reply